
Förderjahr 2020 / Stipendien Call #15 / ProjektID: 5237 / Projekt: Container scheduling using ML-based workload characterization for heterogeneous computer clusters
In my previous blog entry I introduced Edge Computing, and my method of evaluation - simulating an Edge Computing infrastructure using faas-sim. This blog revolves around Serverless (Edge) Computing, the problems we face and concludes by:
- stating our approach of improving scheduling of containers
- presenting our research questions
Serverless (Edge) Computing
Serverless Computing is a cloud platform model which abstracts the underlying infrastructure away from users. Users upload stateless and containerized functions to the platform provider. The provider deploys and scales the application autonomously. The node selection happens automatically, making the underlying scheduling mechanism crucial regarding quality of placements. We consider metrics such as execution time and performance degradation to be important.
A current approach of Kubernetes is to select nodes based on CPU and RAM availability, and is feasible in typical cloud clusters. They are relatively homogeneous in terms of capabilities (CPU, GPU, memory, Disk,…) and therefore perform equally well.

By combining Edge and Serverless Computing, we can guarantee performance advantages and bandwidth reduction made possible by Edge Computing and offer users a convenient method to deploy their functions by relieving them from the selection of appropriate nodes.
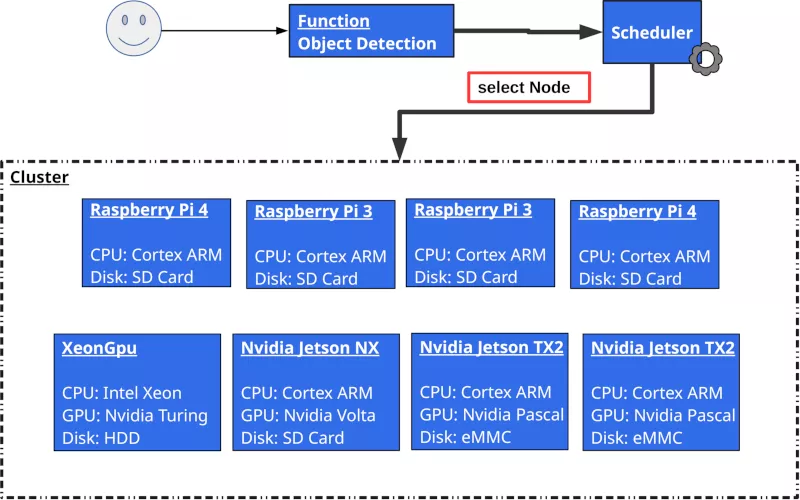
Figure 1 depicts a Serverless Edge Computing scenario. Users upload functions, which are managed by the platform provider. The scheduler selects a node from the heterogeneous cluster - comprised of devices offering different capabilities.
The problem
The caveat of this approach stems from the heterogeneity of hardware - a crucial characteristic of Edge Computing infrastructures. We investigate the problems by performing benchmarks on the testbed provided by TU Wien. You can see a detailed description of the devices in Table 1. Besides common server hardware, the testbed includes embedded AI Hardware and Single Board Computers.
We perform different benchmark experiments to show the difference in computing capabilities. We use galileo to generate requests, and telemd for monitoring telemetry data (CPU/GPU usage, I/O,...). Our focus lies on AI applications, specifically AI Pipelines. Therefore, we profile different Inference (Object detection, speech-to-text transcription), preprocessing and training functions to gather representative data. We use this data for different things, such as:
* feeding our simulation with realistic data
* analyse the effect of heterogeneity on performance
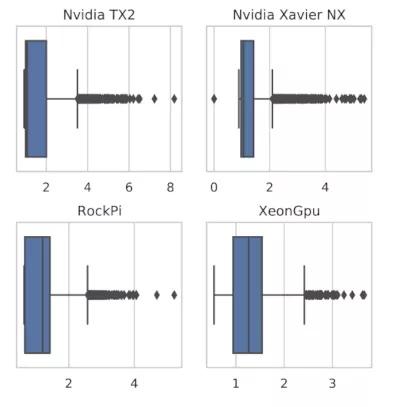
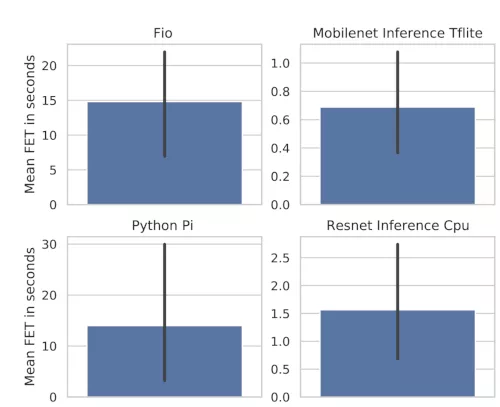
An excerpt of our baseline performance results (execution time) is displayed as barplots in Figure 2. We also measure performance degradation – caused by resource contention - across devices (see Figure 3). The performance degradation is the factor of increase of the execution time compared to the baseline. Both cases demonstrate the impact of different hardware on performance.
This leads us to believe that selecting a node based on CPU/Memory requirements may not be enough anymore. For example, a Raspberry Pi 4 may have the same amount of CPU cores as a cloud VM instance - but differ greatly in performance.
Performance, capabilities and effects of resource contention vary between devices in these clusters - making it hard to reason about placements.
The approach
Therefore, we propose extensions of the Kubernetes scheduler that make it workload-aware with a focus on:
* Performance
* Resources
* Capabilities
Further, we formulate three research questions:
1. What are appropriate black-box metrics for workload characterization?
2. How can we use workload characterization in scheduling functions?
3. What is the impact of a workload-aware scheduler?
The next blog is going to showcase our solutions and answers to our research questions!
References
[1] Philipp Raith, “Container Scheduling on Heterogeneous Clusters using Machine Learning-based Workload Characterization", Diploma Thesis, TU Wien, 2021.

