
Förderjahr 2017 / Stipendien Call #12 / ProjektID: 2418 / Projekt: Decentralised Data Provenance based on the Blockchain
In the previous blog entry, we introduced the W3C PROV model recommendation and gave a short overview of how it can be used to model provenance data. Today we will have a look on how we can query this provenance information once it is stored on a provenance service.
Before we can retrieve provenance records we first need to locate the provenance records. To do this the W3C PROV recommendation defines mechanisms for three different scenarios:
- The resource is accessible via HTTP.
- The resource is available as an HTML document.
- The resource is available as an RDF document.
Here we will only introduce the very first when the resource is accessible via HTTP. Note that a resource is the original data product for which we are tracking data provenance, for example, a news article or a government dataset. To provide its users with the location of the provenance information the resource provider can simply use the HTTP header field Link for provenance information that is accessible via HTTP.
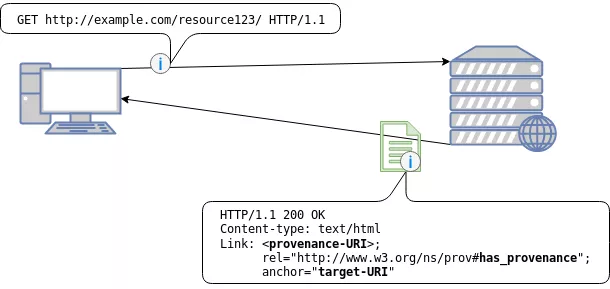
In the figure above we can see how the Link field can be used to directly reference provenance information. The provenance-URI is a placeholder and points to the location of the provenance information whereas the anchor, which is also a placeholder, defines the target-URI which identifies the resource we are looking for. Finally, there is the has_provenance link which defines the relation type of the field. If we substituted with example values we would insert the following values instead of the placeholders.
- provenance-URI: http://example.com/resource123/provenance/
- target-URI: http://example.com/resource123/ (this is the same URI like in the GET request of the client)
Alternatively, the server could also respond with a provenance query service instead as shown in the figure below.
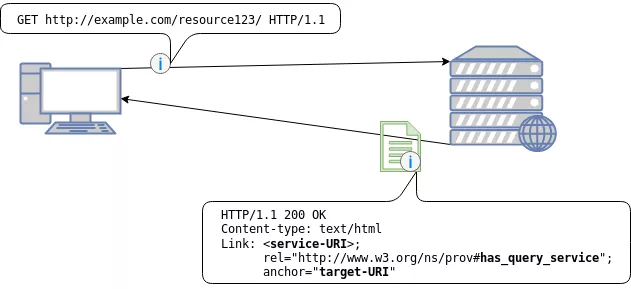
As you can see instead of the provenance-URI the resource server returns a service-URI that points to a provenance query service. Another difference is that the relation type has changed to has_query_service. The anchor stays the same and identifies like before the original resource.
Now that we know how we can locate the provenance information we still have to query the information itself. The W3C PROV recommendation defines two simple ways of doing this. Either by dereferencing the provenance-URI or by querying the service-URI. It is also interesting to mention that the recommendation allows sending simple HTTP queries to the query service as well as more complex SPARQL queries. Going into more detail about querying the service is however out of scope for this blog entry. Instead we will shortly talk about the concept of pingback services. The mechanisms presented so far are all from the viewpoint of the resource owner. They represent how the resource owner would make the provenance information available. However, once the resource is available other instances could start producing additional provenance information. For any user to have all the provenance information the user would also need the provenance information from this additional instances. For example, take a government data set. A newspaper could take this dataset and write some article about this data. The government would provide its provenance information and the news agency would provider theirs. However, the government has no way of knowing about the provenance information of the news agency. Thus anyone querying the provenance information of the government would have a potentially incomplete picture. This problem gets solved by pingback services. By providing another HTTP Link field that holds the URI of a pingback service. Other instances that hold further provenance information can then use this pingback-URI to send back information about where this additional provenance information can be found, as depicted in the figure below.
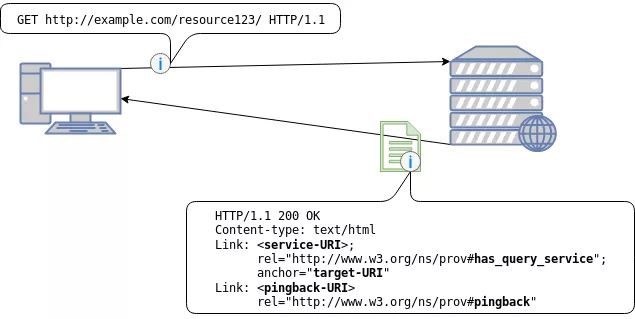
If we consider our previous example the news agency could send back to the government pingback service that they have additional provenance information. If a blogger latter queries the dataset and the provenance information from the government, the blogger would also get informed about the additional provenance information at the news agency and could also retrieve that information.
Svetoslav Videnov

My master thesis aims to combine the advantages of the blockchain with data provenance. The blockchain is a distributed ledger which allows persisting data in an unchangeable way. Data provenance is an approach to track what happened to data and by this allowing to build trust into this data.
