
Förderjahr 2024 / Stipendium Call #19 / ProjektID: 7383 / Projekt: Dynamic Power Management for Edge AI: A Sustainable Self-Adaptive Approach
Over this project, I collected real lab data, built a RL environment, trained an energy-aware PPO agent, and defined a robust evaluation strategy. This final post shows what the agent ultimately learned about adapting performance to available energy.
This post wraps up the project by looking at what all the previous work ultimately led to: how the trained RL agent behaves, how it compares to simple baselines, and whether it actually learned to balance energy and performance.
Big Picture: Performance vs. Survival
Across all evaluation scenarios, the results show a clear and unavoidable trade-off between detection performance (SLA satisfaction) and battery survival. Static baselines sit at the extremes: power-hungry configurations achieve near-perfect confidence but drain the battery quickly, while conservative setups survive longest but deliver almost no useful detections.
The PPO agent consistently positions itself between these extremes. It avoids the inefficiency of random behavior and learns a balanced policy that adapts its behavior depending on available energy.
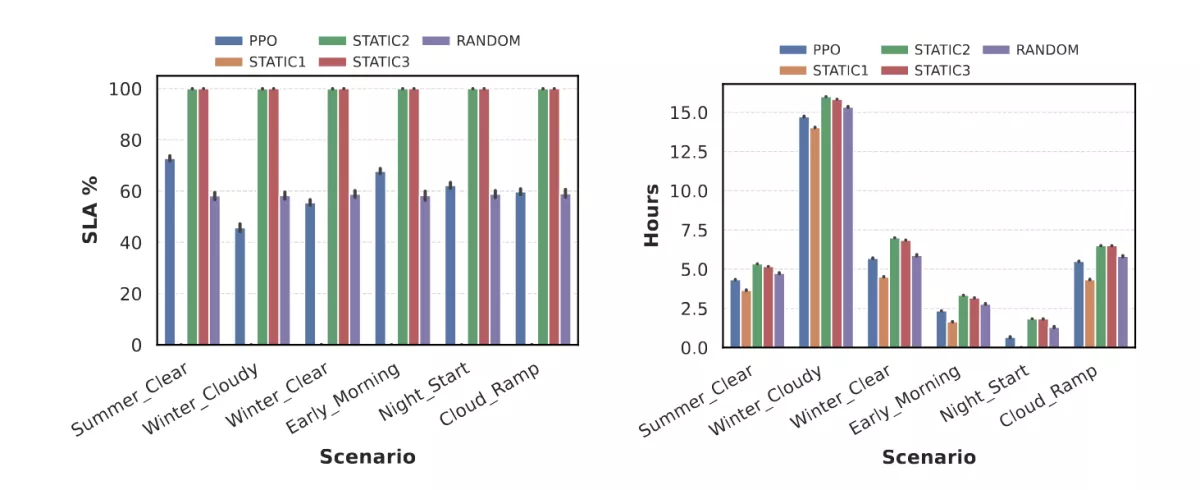
Aggregate Results (24h)
Over multiple 24-hour scenarios, the agent outperforms the random baseline in most conditions and significantly reduces battery downtime compared to high-power static policies. In high-energy scenarios, it delivers strong SLA performance; in low-energy scenarios, it deliberately sacrifices confidence to survive longer. This behavior is intentional and aligned with the training objective. This can be seen in the figures below.
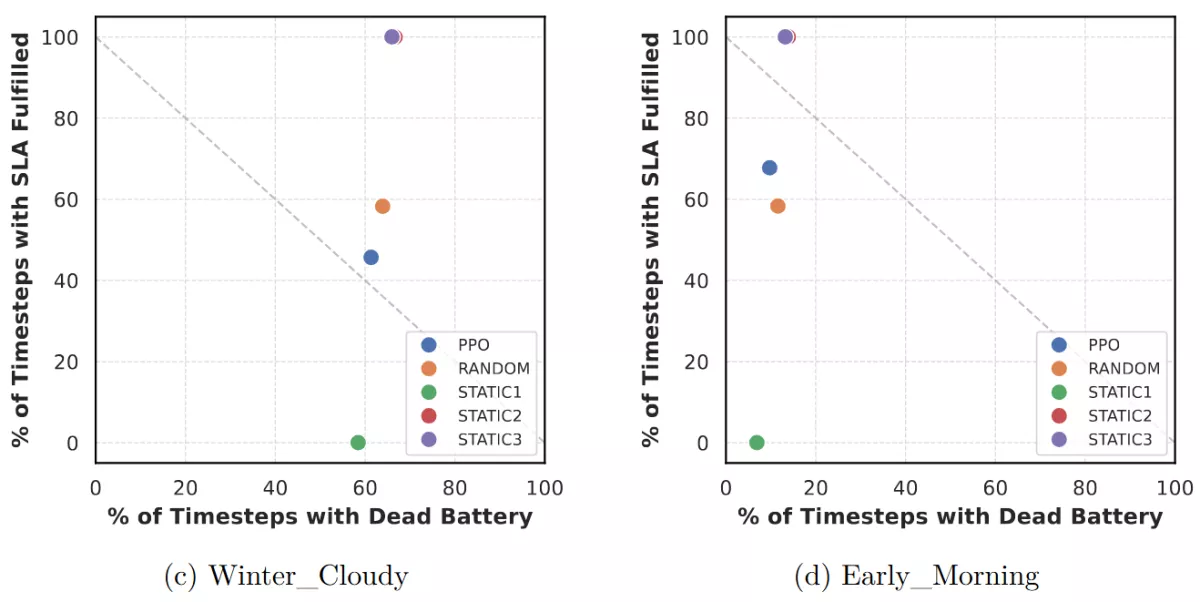
Trade-off Analysis
Plotting SLA satisfaction against battery downtime makes this behavior very clear. Static policies cluster at opposite ends of the trade-off curve, while the PPO agent dynamically shifts its position depending on the scenario. In summer and early-morning settings, it moves toward higher performance. In winter or cloudy conditions, it shifts toward energy conservation. This adaptability is what distinguishes it from non-learning baselines. To demonstrate this, I inserted the corresponding figures for two scenarios with different lighting conditions: "Winter Cloudy" (which, as the name says simulates a cloudy winter day) and "Early Morning", which simulates a sunny day and starts at 4 am.
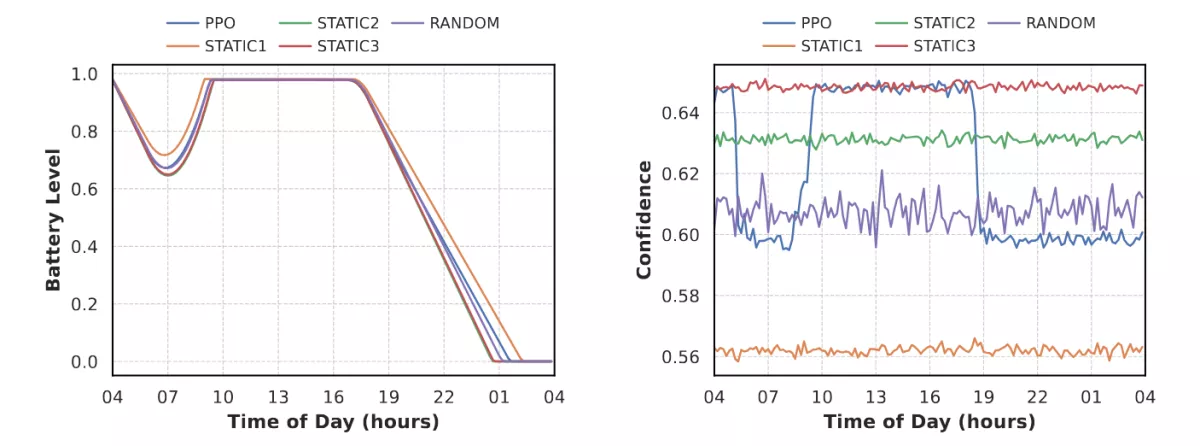
Temporal Behavior: Does the Agent React Correctly?
Looking at 24-hour battery and confidence traces confirms that the agent learned the intended qualitative behavior. It scales down performance during darkness or cloudy periods and scales up once solar energy becomes available. Unlike the random baseline, these changes are consistent and context-aware, not accidental. To show this, I inserted the battery and confidence traces derived from my "Early Morning" scenario:
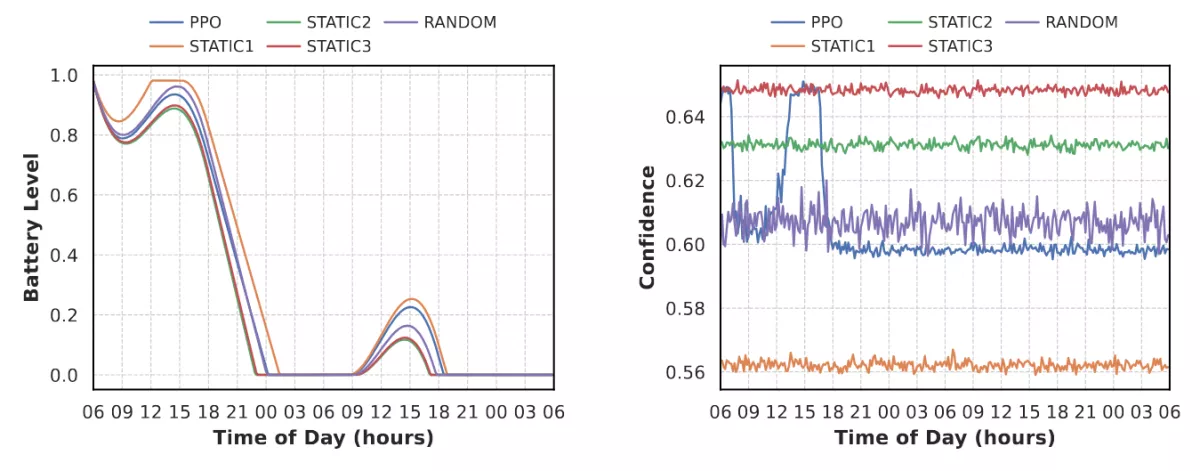
Long-Term Behavior (48h)
The strongest validation comes from the 48-hour evaluation. Here, the agent’s conservative decisions compound over time. While it may not look impressive in the first day, by the second day it recharges earlier, reaches higher battery levels, and survives significantly longer than random or power-hungry baselines. This confirms that the agent learned sustainable energy pacing, not just short-term optimization. This can very clearly be seen in the battery and confidence traces of my "Winter Clear" scenario, which simulates a sunny winter day:
Final Takeaway
The results show that the PPO agent successfully learned a goal-aware, adaptive strategy. It balances survival and performance better than simple baselines, reacts sensibly to changing energy conditions, and demonstrates long-term sustainability. While the system is not claimed to be universally optimal, it proves that learning-based control is a viable approach for managing energy-constrained edge inference.
Thank you for following along on this journey!


