Förderjahr 2021 / Stipendien Call #16 / ProjektID: 5884 / Projekt: Efficient and Transparent Model Selection for Serverless Machine Learning Platforms
This blog post describes part of the qualitative aspect of the evaluation of the platform prototype from the previous post.
The qualitative evaluation contains (among others) these two research questions:
- Which benefits can be achieved in terms of latency by using a weighted model selector compared to a round-robin, random or fixed-choice model selector?
- Which benefits can be achieved in terms of accuracy by using a weighted model selector compared to a round-robin, random or fixed-choice model selector?
To answer these research questions we will evaluate the platform prototype in a partially simulated environment. The platform prototype will be deployed on a Kubernetes cluster, with the models being deployed to different nodes. This resembles a real world deployment which would use the same technology stack.
In a real world deployment though, the models would be deployed to different regions or on the edge, which would result in different latencies. To simulate those different latencies between the models and the selector, we will use the Linux Traffic Control (tc) tool. This tool allows us to simulate different network conditions between the nodes. To test different latency scenarios at once, we will deploy the platform onto 4 nodes, with the selector and the client being deployed to the same node. The other three nodes will host the models, with the latency between the selector and the models increasing with each node.
RQ1
To evaluate how well the weighted model selector performs in terms of latency compared to the other selectors, we look at the empirical cumulative distribution of request latencies, when advising the MuLambda selector to select solely based on latency.
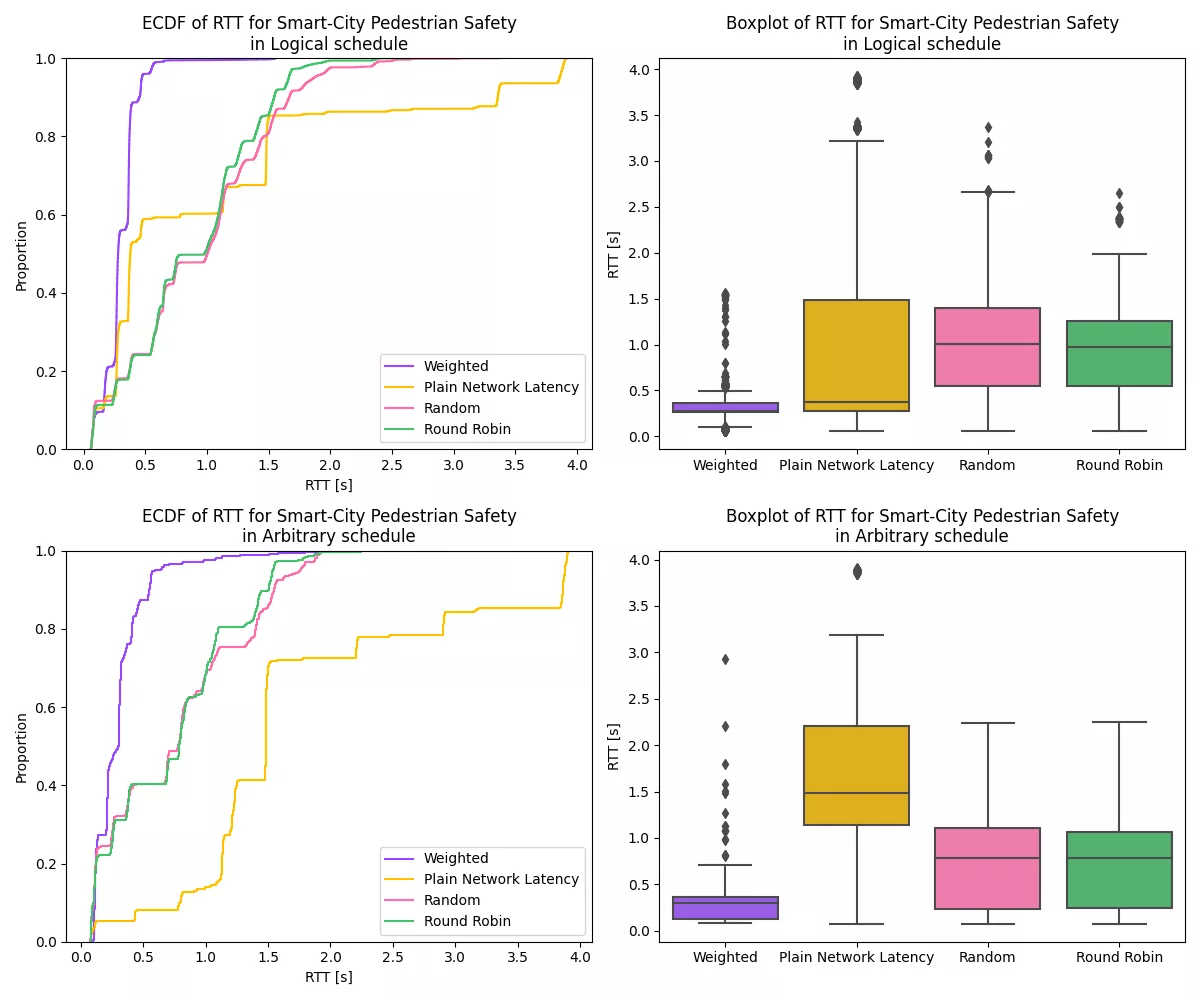
As we can see in the image above, the weighted model selector performs best in terms of latency. This holds true for the hand-picked “Logical” schedule as well as for the “Arbitrary” schedule which we randomly pre-generated. Most of the requests are served in less than 300ms, with the 95th percentile being at around half a second. We can also notice a clear distinction to the distributions of the other selection algorithms. The algorithm which produces the second most requests with a latency of less than half a second is the selector which chooses solely based on host latency. However, we can notice that the distribution of the plain net latency selector is much more spread out. The 95th percentile of the plain net latency selector is even the worst of all selectors. For the remaining two selectors we notice a very similar distribution between them, having a median latency of around a second and a 95th percentile of around 1.8 seconds.
For better understanding of these cumulative distribution functions we can also look at the time series data of the latencies in a given experiment in the image below.
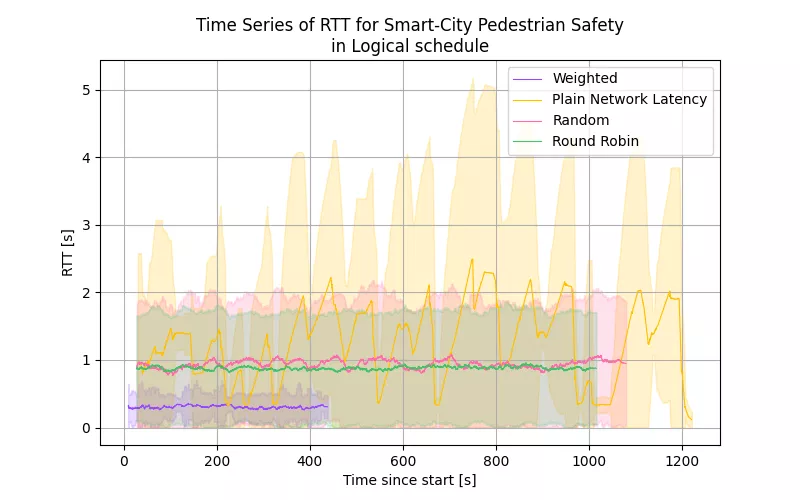
The experiment ran in the “Logical” schedule with all of the selectors. The first difference that we can notice is the length of the different experiments. The weighted model selector experiment took roughly 450 seconds, while the other experiments took more than double the time. We can also see the reason for that in the time series data, as the weighted model selector has a much lower average round trip time than the other selectors. The second noticeable difference is in the confidence intervals of the data. We can see that the weighted model selector has much more stable latencies than the other selectors. Here we can also see the reason for the increased amount of low latency response times for the plain net latency selector. The variance of the results of this selector is much higher than the other selectors, which leads to a lower median. This comes at the cost of having a significantly increased amount of high latency results.
Answer: We can see that using the weighted model selector with a focus on latency leads to a noticeable improvement in latency compared to the other selectors. In general, the weighted model selector produces the lowest average latencies of all, the lowest median latencies of all and the lowest 95th percentile of all selectors under test. This holds true for all schedules, but we can notice it most for the “Logical” Schedule. Using only the host latency as a metric can lead to better average latencies, however, in schedules where low-latency hosts serve models with a high delay this can produce worse results than all other selectors.
RQ2
To evaluate how well the weighted model selector performs in terms of accuracy compared to the other selectors, we look at the empirical cumulative distribution of accuracies, when advising the MuLambda selector to select solely based on accuracy.
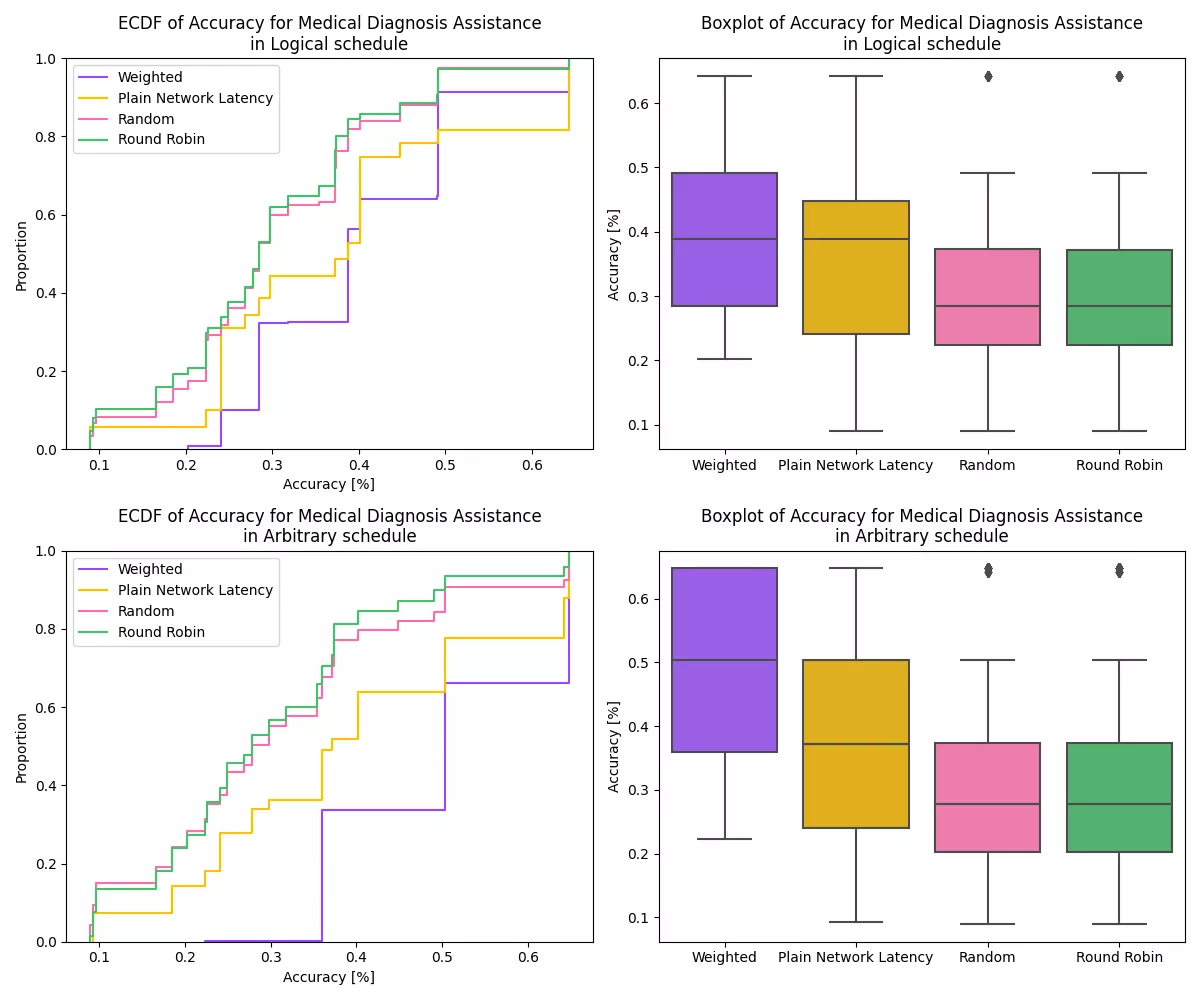
We can immediately notice in the image above that the curve of the weighted model selector lies significantly below the curves of the other selectors in both displayed schedules. This means that a higher share of the requests receives results with a higher accuracy.
Answer: We can see that using the weighted model selector with a focus on accuracy leads to a noticeable improvement in accuracy compared to the other selectors. In general, the weighted model selector produces the highest average accuracies of all, the highest median accuracies of all and the highest 95th percentile of all selectors under test.