
Förderjahr 2022 / Stipendien Call #17 / ProjektID: 6424 / Projekt: Energy-efficient IoT by Continual Learning for Data Reduction
Continual Learning aims to improve Machine Learning model performance in the long term. However, IoT devices lack the capabilities to train the models themselves. Hence, we introduce a modular architecture for client-server model synchronization.
What is the problem?
The number of active IoT devices is rising every day. Moreover, the ever-decreasing size of these devices enables more and more applications: precision agriculture, intelligent medical devices, smart infrastructure, and industrial IoT are just a few examples. Many share the need to take periodic measurements using sensors for monitoring purposes and only have wireless communication available.
As a user, we want to observe these measurements. Assuming a sampling rate of minutes, seconds, or even milliseconds, naively sending all measurements from the devices to a base station leads to multiple issues: First, high network traffic can lead to network congestion. Second, wireless communication consumes energy. In the era of climate change, increasing communication and energy efficiency is in itself a desirable goal. However, if IoT devices are battery-driven, it additionally increases their lifetime and reduces their cost.
Data Reduction by Data Prediction
We can reduce the required communication by using data prediction for data reduction: Both the base station and the sensor node have an equivalent instance of a model for data prediction. The model only requires past measurements to predict future measurements. For every sampled measurement, the sensor node compares it with the prediction and directly communicates to the base station if the difference exceeds an application-dependent threshold metric.
In the past, sensor nodes required relatively simple prediction algorithms due to limited computational resources. Nowadays, frameworks like TensorFlow Lite enable deploying machine learning (ML) models on devices the size of microcontrollers. By leveraging the higher expressibility of ML models, we can reduce the transmitted data further.
What happens in the long run?
We face one problem with ML models: if the data distribution of the measurements changes (think climate change), we need to adapt the model. Otherwise, the model will become useless.
Continual Learning (CL) tackles this challenge by continually accommodating new knowledge while retaining previously learned experiences. Within this active area of research, many different approaches exist, all having different trade-offs. However, delivering an updated model to a sensor node entails a nontrivial data transfer that must be justified by improved prediction accuracy.
What is my contribution?
Given the described problem, I will implement a framework to simulate different deployment scenarios. The framework will be written in Python and use the TensorFlow (i.e., Keras) library for ML. After finishing my thesis, the framework will be provided as open source.
Architecture
The following diagram provides a high-level view of the framework's architecture:
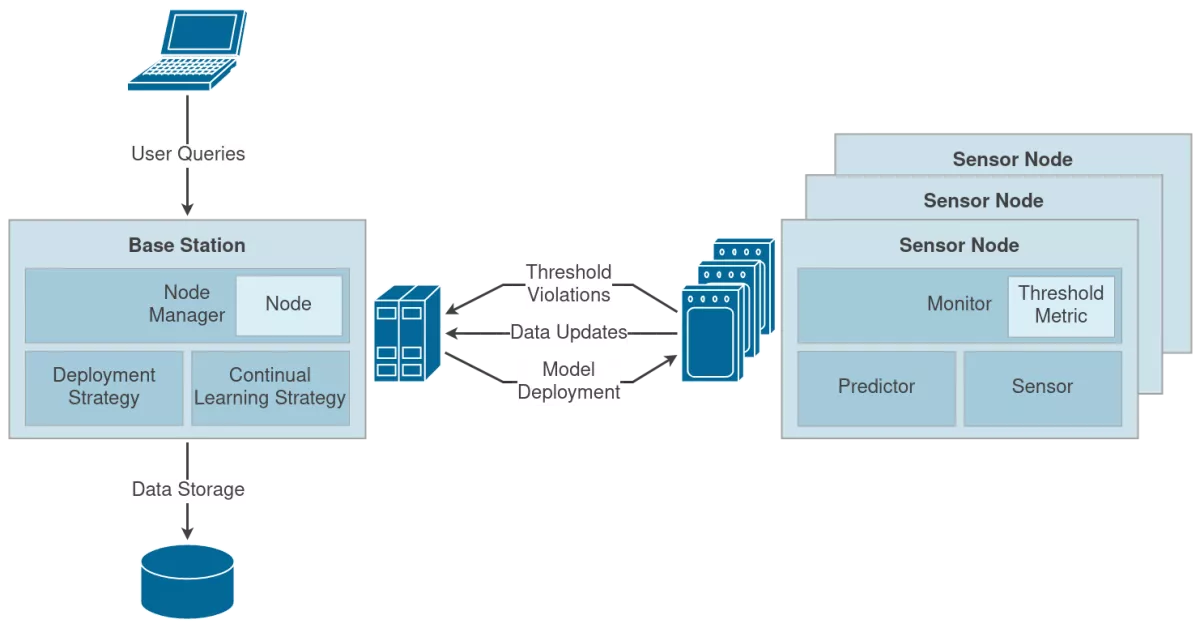
Within the Base Station, the Node Manager manages multiple deployed Sensor Nodes. It maintains the currently deployed prediction model for each node to answer user queries with the predicted measurements. Based on the defined Deployment and Continual Learning Strategy, the Node Manager will update and re-deploy models to individual Sensor Nodes.
Each Sensor Node has a Sensor component used for taking measurements. The Monitor component uses these measurements and the predictions from the Predictor to check whether the specified Threshold Metric is violated.
This modular architecture should enable others to easily extend the framework with custom strategies and metrics for other application scenarios. I hope that it will prove helpful for further research in this area.

