Förderjahr 2024 / Projekt Call #19 / ProjektID: 7207 / Projekt: HaSPI
Recently, we were able to present and discuss the technological concept of HaSPI with our research colleagues at the University of Applied Sciences St. Pölten as part of an interactive data intelligence research seminar series. Below you find a summary of the presentation.
With HaSPI we present a new method using imitation learning to classify sequential data such as articles, blog posts or comments. Imitation learning approaches have proven particularly useful when dealing with sequential data and are now a vital part of efficient large language model training (Wulfmeier et al. 2024).
Behind the Scenes: Key Theoretical Principles
Reinforcement Learning Basics
A reinforcement learning agent interacts within a specific environment. This environment presents a state and the agent then performs an action for which it receives a (positive or negative) reward signal before it is confronted with the next state (Figure 1). During the training process, the agent develops specific behaviour patterns that aim at maximising the sum of rewards it receives during the process (Sutton and Barto 2018).
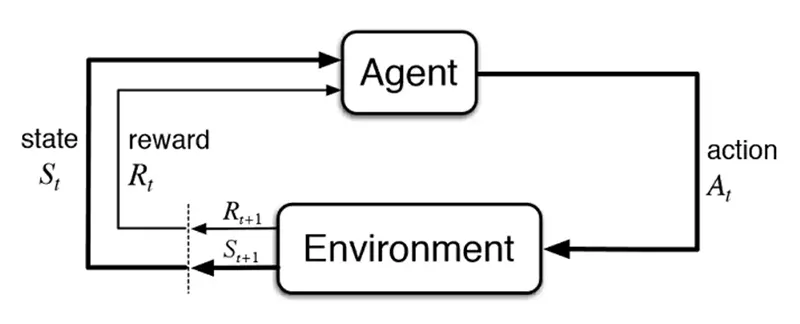
Some important terms (all based on Sutton and Barto 2018) in this context are:
- Policy: An agent's “decision-making ruleset”, which describes how it behaves in its environment.
- Return: The total reward the agent expects to collect during training.
- Value function: Describes the “value” of a state. It indicates how much return the agent can expect if it is in that state and subsequently follows a certain policy.
Imitation Learning Basics
Training a reinforcement learning agent from scratch can be time consuming, especially for complex tasks with various possible courses of action. Therefore, it often makes sense to incorporate existing expert knowledge and imitate the desired behaviour. This is called imitation learning. Based on the observation of the expert’s behaviour, the agent estimates the associated reward function which is then used to develop a suitable policy (Sutton and Barto 2018).
The Key Concept: Occupancy Measure
A major challenge is that the policy cannot be accessed directly by the agent. That is why the occupancy measure comes in handy – it expresses how many times an agent encounters a state and performs a certain action. It thus describes the behaviour of the agent and, thus, the policy. Using the occupancy measure, the non-accessible policy can be represented via the easily computable value function (Janz et al. 2023). The value function evaluates a given policy and is therefore essential for developing optimal behaviour. Consequently, the occupancy measure acts as a “direct shortcut” from the value function to the agent's (optimal) policy. Hence, this measure is a vital foundation for the classification approach we aim to develop.
How to Design a Classifier?
Based on these considerations, we have developed the core idea of our hate speech classifier (see Figure 2): Once a set of possible reward functions has been defined, an agent is trained on a suitable data set. The now generated policy serves as an orientation framework for the agent. During the subsequent training, when the agent is confronted with various bits of content, it analyses whether these samples could also have originated from such a hate speech policy. The metrics of both policies are then compared to each other. If the difference does not exceed a defined threshold, there is a very high probability that the sentence or text passage in question was also generated from hateful behaviour. It is thus classified as hate speech.
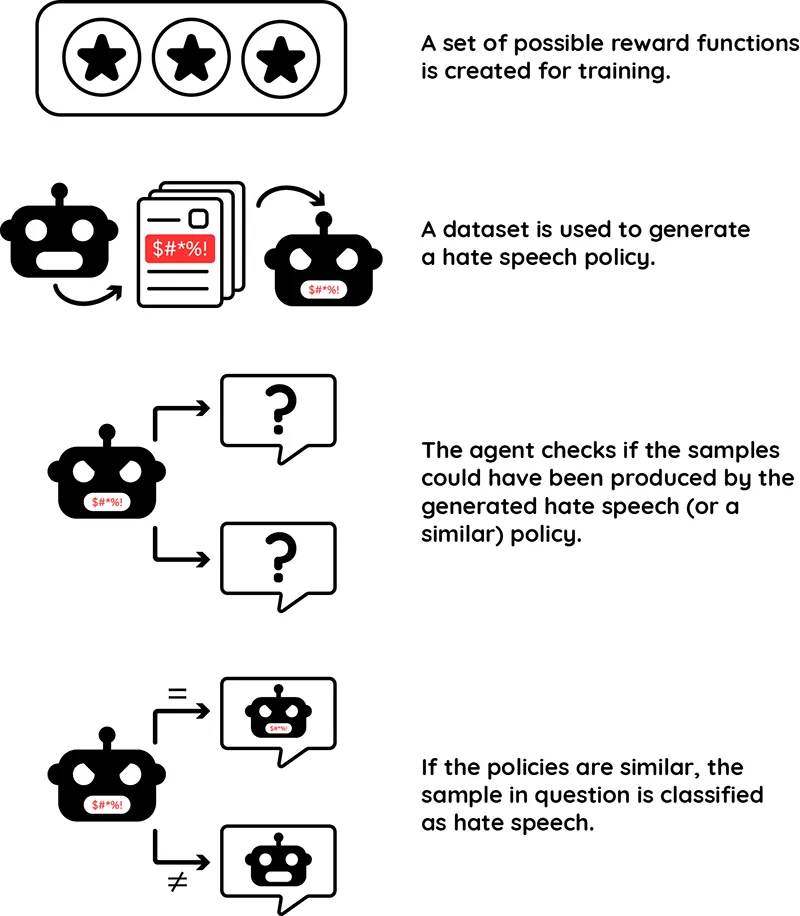
During the seminar we discussed this process in detail as well as several open questions. Altogether, we see great potential in the method, since it could be applied not only to hate speech detection but also to other complex, context-dependent issues.
References
D. Janz, J. Kirschner, C. Szepesvár, A. Ayoub, V. Tkachuk, “Lecture Notes of CMPUT 605: Theoretical Foundations of Reinforcement Learning W2023.”, 2023. Accessed: March 03, 2025. [Online]. Available: https://rltheory.github.io/
R. S. Sutton and A. G. Barto, Reinforcement Learning: An Introduction. MIT Press, 2018.
M. Wulfmeier, M. Bloesch, N. Vieillard, A. Ahuja, J. Bornschein, S. Huang, A. Sokolov, M. Barnes, G. Desjardins, A. Bewley, S. Bechtle, J. Springenberg, N. Momchev, O. Bachem, M. Geist, M. Riedmiller, “Imitating Language via Scalable Inverse Reinforcement Learning”, in Advances in Neural Information Processing Systems 37. Vancouver, Canada: Neural Information Processing Systems Foundation (NeurIPS), 2024, pp. 90714–90735. doi: 10.52202/079017-2880