
Förderjahr 2025 / Stipendium Call #20 / ProjektID: 7859 / Projekt: Intellectual Property Protection in Open Data Sharing
Why Data Fingerprinting Matters
When organisations share datasets, whether for research, collaboration, or machine learning, one critical question arises: what happens if the data leaks?
Unlike traditional digital media, structured datasets (tables with rows and columns) are particularly difficult to protect. Once shared, copies can be redistributed, modified, or combined with others, often without any trace of their origin.
This is where data fingerprinting comes in. Instead of restricting access, fingerprinting embeds subtle, recipient-specific marks directly into the data. If a leak occurs, these marks can be extracted to identify the responsible party.
However, designing a practical fingerprinting system is not trivial. It must satisfy several competing requirements:
- Effectiveness – reliably identify the data recipient
- Fidelity – preserve the statistical properties of the data
- Utility – keep the data usable for downstream tasks
- Robustness – withstand attacks and modifications
- Blind detection – work without access to the original dataset
Balancing all of these simultaneously has been a long-standing challenge in the field.
The Core Idea Behind NCorr-FP
NCorr-FP (Neighbourhood-based Correlation-preserving Fingerprinting) introduces a key shift in how fingerprints are embedded.
Instead of modifying data values randomly or globally, it operates locally and context-aware: It uses similar records (neighbourhoods) and attribute correlations to decide how to modify values.
Imagine modifying a person's income in a dataset. A naive method might slightly tweak the value randomly. But this could break relationships with other attributes like age or education. NCorr-FP instead:
- Finds similar records (same context)
- Looks at plausible alternative values
- Chooses a replacement that fits naturally into the data distribution
This makes the fingerprint statistically invisible, hard to remove and consistent with real-world data patterns.
How Fingerprints Are Embedded
At a high level, embedding works in three steps:
1. Pseudo-random selection: Only selected records and attributes are modified using a secret key.
2. Neighbourhood construction: For each selected value, similar records are identified based on correlated attributes.
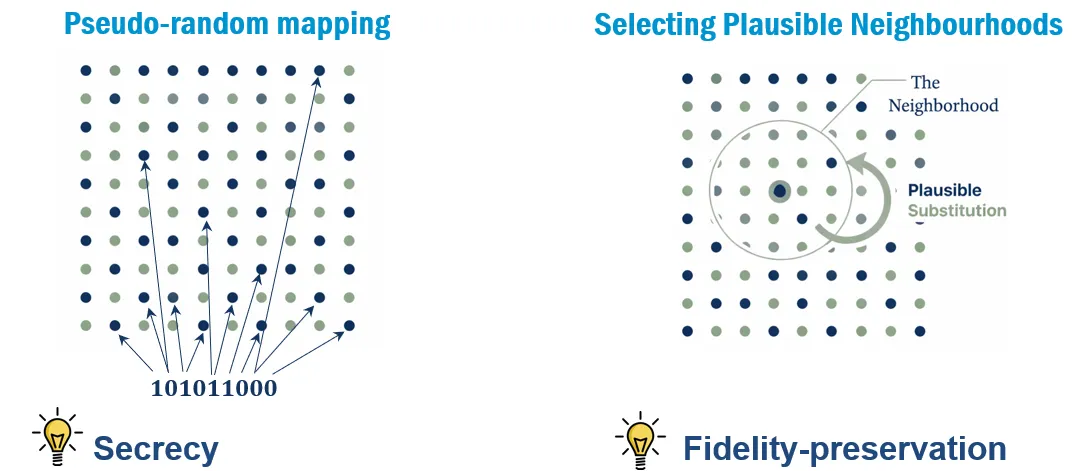
3. Density-based encoding: Candidate values are split into high-density (common) values low-density (rare) values. A fingerprint bit determines where to sample from:
- bit = 1 → common values
- bit = 0 → rare values
This creates a binary encoding hidden in the data distribution itself.
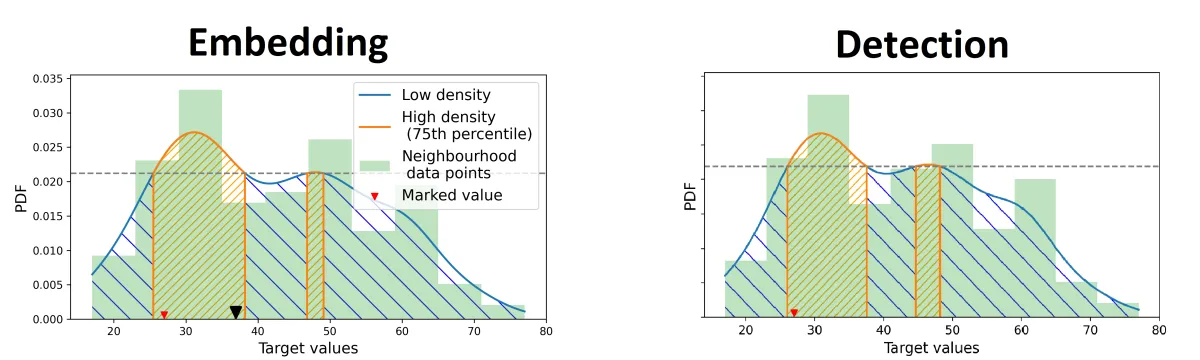
Blind detection
One of the strongest properties of NCorr-FP is blind detection. This means that the original dataset is not needed to recover the fingerprint.
Instead, the algorithm:
- Reconstructs neighbourhoods from the fingerprinted data
- Recomputes density regions
- Infers whether a value belongs to a high- or low-density region
- Recovers bits via majority voting
Even if parts of the dataset are modified or deleted, enough redundant signals remain to recover the fingerprint.
Evaluation of NCorr-FP
High fidelity: Changes follow real data distributions, preserving statistics and correlations.
Robustness: Fingerprints remain detectable even after large data deletions or modifications, attribute removal or adaptive attacks:
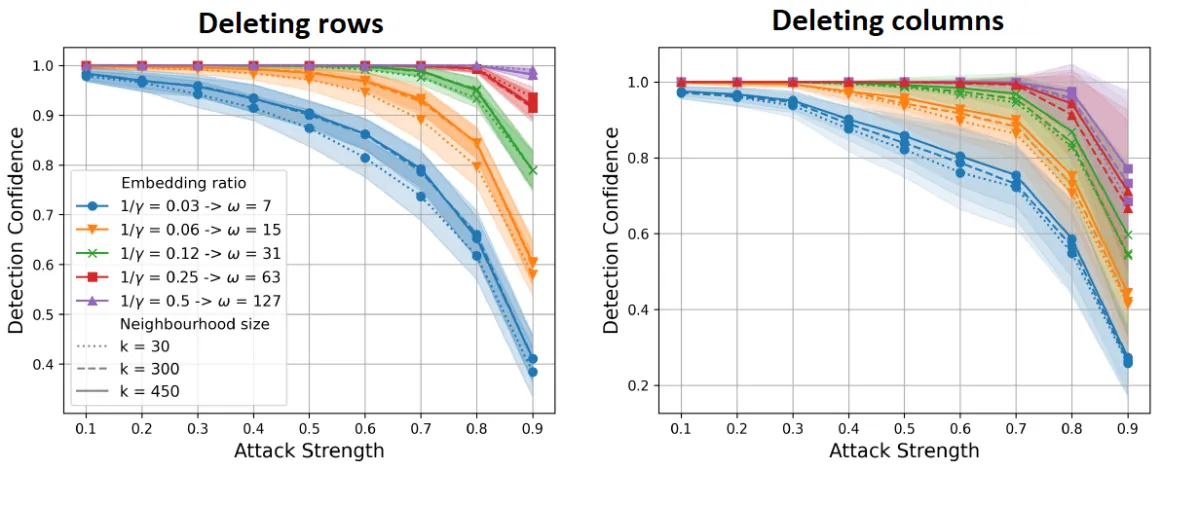
Utility preservation: Machine learning performance is largely unaffected.
Mixed data support: Works with both numerical and categorical attributes.
Key Takeaways & Outlook
NCorr-FP represents a significant step forward in data fingerprinting:
- It embeds fingerprints in a statistically natural way
- It preserves data quality and usability
- It achieves strong robustness against attacks
- It enables blind and reliable detection
Most importantly, it demonstrates that data protection and data utility do not have to be a trade-off.
The full paper is currently under review and available as a preprint.

