Förderjahr 2020 / Project Call #15 / ProjektID: 5214 / Projekt: MLReef
Mit der BETA Version von MLReef wurde ein weiterer, sehr wichtiger Meilenstein erreicht!
Beta Release von MLReef (MVP erreicht!)
Das Ziel von MLReef ist die gesamte Wertschöpfungskette von Künstlicher Intelligenz (KI) Modellen abzudecken. Mit unserem BETA Release Anfang Februar 2021 sind wir diesem Ziel deutlich näher gekommen, denn wir haben auch gleichzeitig unseren MVP - Minimal Viable Product - damit erreicht.
Die Bemessung von unserem MVP hängt von zwei grundlegenden Faktoren ab. Einerseits von einer gewissen Bandbreite an Funktionen und andererseits and eines festgelegten Reifegrades (gemessen an Stabilität und Nutzerfreundlichkeit).
MVP Funktionen - Die KI Wertschöpfungskette
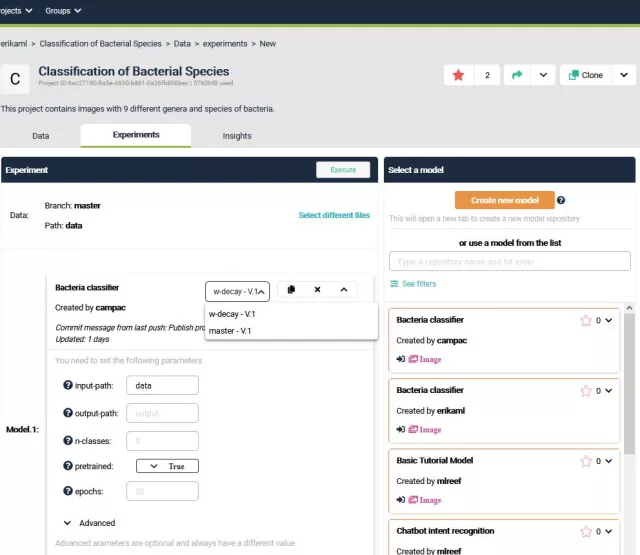
Mit der BETA können Nutzer eine bedeutende Breite an KI Anwendungen und dafür notwendigen Entwicklungsfunktionen abdecken. Es besteht im Grundsatz keine Anwendungslimitationen, so können Natural Language Processing (kurz NLP), Bilderkennungsmodelle, Zeitreihenanalysen und viele mehr entwickelt werden. Der einzige limitierende Faktor, die Funktionen müssen als Python Scripts publiziert werden - Python ist in Machine Learning die meist verbreiteste Entwicklungssprache.
Für diese Anwendungen stehen in der Beta Version von MLReef folgende Entwicklungsfunktionen bereit:
- Hosting von Datensätzen mittels GIT Repositorien. Hier können Nutzer ihre Daten hochladen und alle üblichen GIT Funktionen nutzen, wie z.B. eine neue Branch erstellen, simultan an einem Datensatz arbeiten und die Änderungen ohne Reproduzierbarkeit zu verlieren wieder zusammenführen.
- Nutzung von Data Pipelines. In MLReef stehen zwei Klassen von Datapipelines zur Verfügung. Einerseits um "Data pre-processing" durchzuführen, also die Daten automatisiert abändern um neue Datensätze zu generieren. Und andererseits können Nutzer ihre Daten visualisieren. Hier geht es insbesondere Darum, die Verteilung von Daten verstehen zu können um auch ein Modell dann richtig zu trainieren.
- Trainings / Experimente Pipelines. Ähnlich wie die Data Pipelines können Nutzer Modelle trainieren und somit Experimente schaffen. Dafür stehen dem Nutzer die Experiment Pipeline zur Verfügung, wo state-of-the-art KI Modelle von der Community publiziert und von jedem anderen Nutzer sehr einfach genutzt werden können.
- Experiment tracking. Alle Experimente werden aufgezeichnet und stehen übersichtlich den Nutzer jederzeit zur Verfügung. Alle relevanten Metriken, wie z.B. welche Version der Daten wurde genutzt, welche Version meines Modells wurde trainiert und mit welchen Hyperparametern. Der Nutzer kann einfach jeden Schritt nachverfolgen und das generierte Modell herunterladen und zum Einsatz bringen.
- Publizieren von eigenen Funktionen. Nutzer können eigenen Funktionen in dafür vorgesehene GIT Repositorien ablegen. Um diese Funktionen auch in den Pipelines (Daten + Experimente) zu nutzen, müssen sie aber vorher publiziert werden. Der Publizierungsmechanismus ist einer der essenziellen Funktionen, welche erst die Community-generierte Funktionen für alle anderen Nutzer als "working code" zur Verfügung stellt. Hinzu kommt, dass damit erstmalig CI/CD Mechanismen in einer KI Entwicklungsplattform implementiert worden ist. Damit implementieren wir schon im DevOps bekannte Operationalisierungsmechanismen in den "MLOps" Bereich.
Was kommt als nächstes?
In der jetzt folgenden Beta Phase fokussieren wir uns auf die Stabilisierung der Plattform, insbesondere aber auf die Funktionsweise der Pipelines. Diese müssen sehr robust und effizient sein. Dafür haben wir in den letzten Monaten diese in Kubernetes implementiert um, allerdings auch, skalierbar zu sein. Weiters wollen wir das on-boarding der Nutzer vereinfachen und weitere ML Inhalten z.b. ganze Anwendungen aber vor allem Code Module als publizierte Funktionen unserer Nutzerbasis bereitstellen.