
Förderjahr 2022 / Stipendien Call #17 / ProjektID: 6335 / Projekt: Question answering over knowledge graphs
Nowadays, the continuous increase in computational power, the rise of social media, and the reduce storage costs have led to an overwhelming flow of data. As the amount of data is increasing, the importance of finding information on the web is growing exponentially. Since the advent of the web, a vast number of techniques and approaches have been designed and developed to provide search services on the web in order to explore and fetch the desired information.
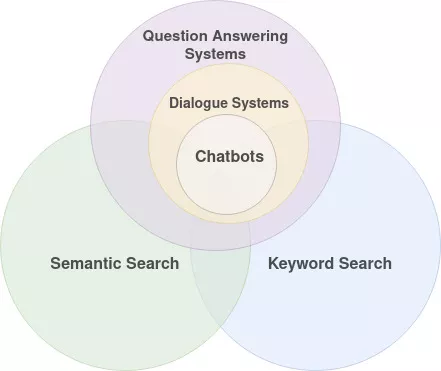
This blog post describes different search services from the early days of the web to the present based on our published paper titled by “Interactive Search on the Web: The Story So Far”. In this blog post, we summarize our paper and categorize the search services into keyword search engines, semantic search engines, question-answering systems, dialogue systems, and chatbots.
Are you ready? So, let’s start the story!
Keyword Search Engines
In the early days of the web, the content of the web was fully indexed and a list of links was hosted on specific web servers. For example, Archie, as one of the first search engines, was just an index of File Transfer Protocol (FTP) sites. These early search engines paved the way for creating keyword search engines. Thus, the indexing approachs were replaced by keyword search engines. Keyword search engines, known as syntactic search engines, can be viewed as a form of text search on the web by creating text queries and retrieving information using keywords.
The core components of keyword search engines include the information collection component, indexing component, and ranking component. First, in the information collection component, web pages are browsed by web crawlers to collect pages. The collected pages are stored and indexed in order to improve the speed of retrieval. Then, the ranking component uses ranking techniques to provide a ranked list of results from most relevant to least relevant. The pages can be ranked based on their content and keywords, their usage and users’ past navigation and retrieval patterns, and the links between them.
Semantic Search Engines
The vision of the semantic web is to create a machine-understandable web and semantic search targets to understand contextual meanings of the user query and improve search accuracy through consuming machine-readable web pages and semantic annotations.
As a high-level view, a semantic search engine crawls, discovers, and collects documents. Here, hybrid crawlers have to be used to harvest structured and unstructured data effectively. Then, the search engine analyses and indexes all the retrieved documents using the meaningful relationships between the resources and the documents’ metadata. The primary indexing approaches include ontology-based indexing, entity-based indexing, and textual-based indexing. Later, the indexed data are stored as a knowledge base so that the knowledge can be queried. To construct a knowledge base, several challenges such as schema alignment, entity matching, and entity fusion have to be addressed. Moreover, several semantic and statistical metrics are used to rank the results. The ranking approaches can be grouped into entity ranking, relationship ranking, and document ranking.
Question Answering Systems
Question answering systems, as an extension of search engines, can be viewed as natural language semantic search engines. These systems allow users to meet their information needs by naturally asking questions and receiving answers to questions instead of a ranked list of results. The knowledge sources that question answering systems exploit to find answers can be unstructured such as text documents, structured such as tabular data, or semi-structured such as RDF knowledge graphs (discussed in the previous blog post).
Question answering systems have a pretty long history. However, this blog post only describes techniques introduced to develop question answering systems over knowledge graphs. These techniques are grouped into traditional techniques, information retrieval-based techniques, and semantic parsing-based techniques. An example of the traditional techniques is rule-based methods that rely on pre-defined rules to answer questions. The information retrieval-based approaches mostly use neural networks to retrieve all candidate answers and then rank them to select the best answer. The semantic parsing-based techniques conceptualize the task of question answering to parse questions and convert them into structured queries (e.g., SPARQL queries discussed in the previous blog post).
Dialogue systems
Dialogue systems, as a subset of question answering systems, communicate with users through dialogue or conversation. A high-level process model of dialogue systems consists of three main layers, including the user experience layer, the conversation engine layer, and the data layer. The user experience layer is responsible for the user’s input and the dialogue system’s output. The conversation engine layer analyses the user input, keeps the track of the conversation to decide what to answer to the user, and then generates a natural language answer. Moreover, all the data is stored in the data layer.
Chatbots
Chatbots are the most straightforward kind of dialogue systems that imitate human-human interactions and help users fulfill a particular task. Chatbots have a long history starting with ELIZA in 1966 to ChatGPT in 2022. In our paper, we group the introduced methodologies and algorithms to design and develop chatbots into parsing methods, pattern-matching methods, ontology-based methods, probabilistic methods, and neural-based methods that more details are discussed in the paper.
A high-level process model for chatbots has four core components, including the natural language understanding component, dialog management component, chat engine component, and response generation component. The user’s input is analyzed by the natural language understanding component. The output is the identified intention and associated information that is passed to the dialogue management component. This component keeps the track of the conversation’s context. This implies the current intent and identified entities. The heart of the chatbot is the chat engine that executes the user’s intended action. Based on the action, single or multiple possible responses are transferred to the response generation component. This component uses natural language generation approaches to construct a personalized response based on responses. A personalized response has to have a proper writing style and emotions and be grammatically correct.

