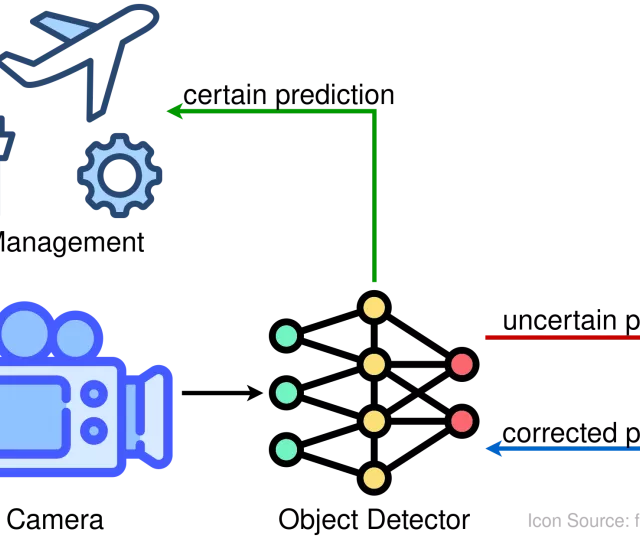
Förderjahr 2023 / Stipendien Call #18 / ProjektID: 6885 / Projekt: Increasing Trustworthiness of Edge AI by Adding Uncertainty Estimation to Object Detection
Four different uncertainty estimation approaches have been tested across six datasets and eight metrics. The surprising conclusion was that the simplest approach performed the best.
Here, we present the conclusion of our work on Increasing the Trustworthiness of Edge AI by Adding Uncertainty Estimation to Object Detection. In this blog, we provide a brief summary of the methodology and then discuss the results.
Methodology
In our evaluation, we take four different models, six datasets to train and evaluate on, and eight different metrics to quantify and compare their performance.
Models
- Baseline [1]: We use the base model YOLO11n and only re-interpret its output as a proxy for uncertainty estimation (1-confidence).
- Ensemble [2]: We replicate network components and compare their disagreement on the same input.
- MC Dropout [3]: Enabling uncertainty estimation by sampling a probabilistic network multiple times.
- EDL MEH [4]: Evidence learning allows for efficient uncertainty estimation in this approach through direct prediction.
Datasets
Our evaluation concerns a domain-shift scenario, where we train on one dataset and evaluate on a dataset with a different domain. Such domain changes can occur due to variations in weather conditions, where the model is trained on images with clear weather conditions and then evaluated on a dataset with rain or fog. Autonomous driving is the common theme among all datasets, as it represents a safety-critical use case perfectly suited for real-time Edge computing.
We train all four models each on datasets with mostly clear weather conditions:
- Cityscapes [5]: Traffic scenes in European (mostly German) cities.
- KITTI [6]: Driving scenes from Karlsruhe/Germany.
Then we introduce the domain shift by evaluating all models on the datasets of:
- Foggy Cityscapes [7]: Adding a fog overlay to images.
- RainCityscapes [8]: Raindrops and streaks are put over the image.
- BDD100K [9]: Large-scale dataset with varying weather conditions.
- nuImages [10]: Large dataset with images captured from multiple angles.
Metrics
For general object detection performance, we measure:
- Precision (P) [11]: Predictions are precise when few false positive detections are made.
- Recall (R) [11]: Recall rewards for finding all ground truth objects.
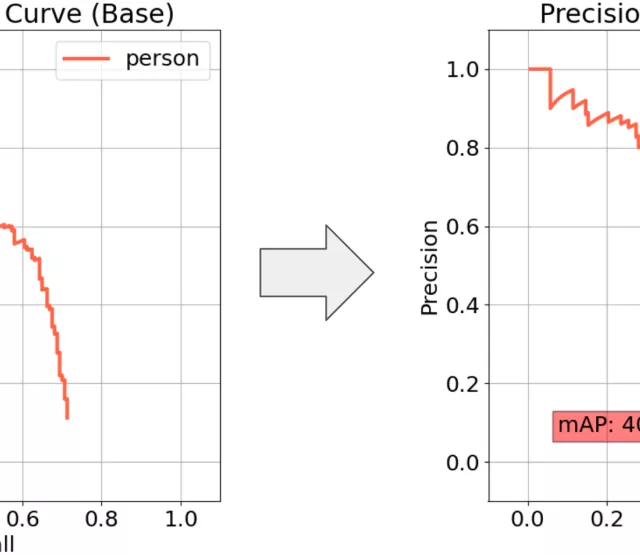
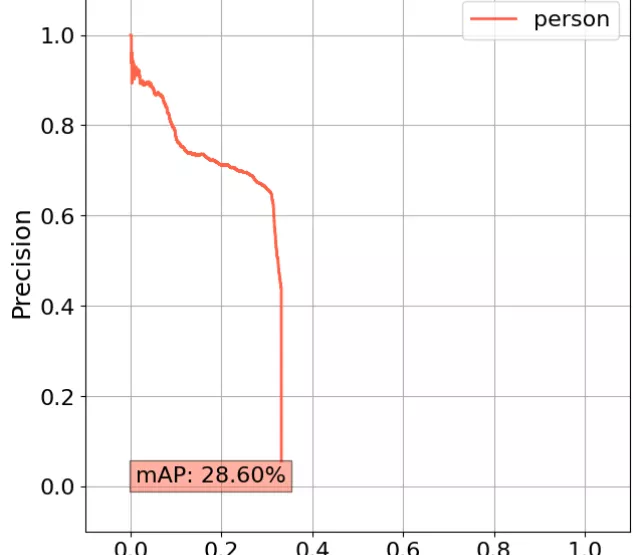
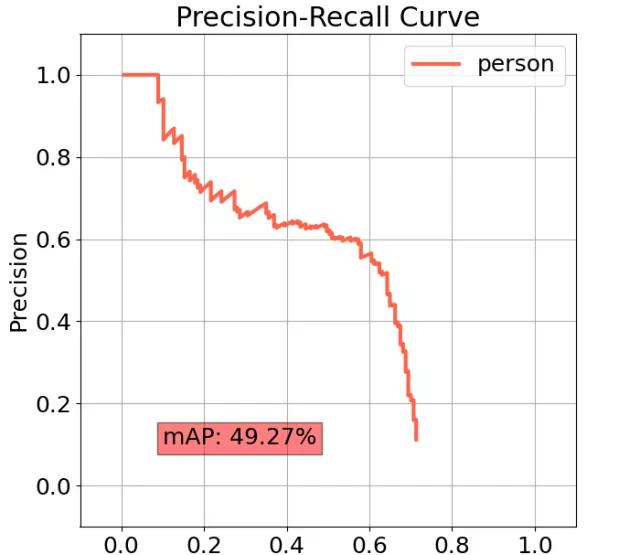
- Mean Average Precision (mAP) [12]: The area under the precision-recall curve (for IoU=50%).
- Framerate (FPS): Images per second that the model can process.
We selected multiple metrics suitable for uncertainty estimation from the literature:
- Minimum Uncertainty Error (mUE) [13]: Using uncertainty to distinguish correct and incorrect detections.
- Area Under the Receiver Operating Characteristic (AUROC) [14]: True positive rate vs false positive rate plotted as a curve.
- False Positive Rate at 95% True Positive Rate (FPR95) [15]: Given a 95% recall, what is the corresponding false positive rate?
- Excess Area Under the Risk-Coverage Curve (E-AURC) [16]: Showing the calibration of uncertainty estimates.
Results
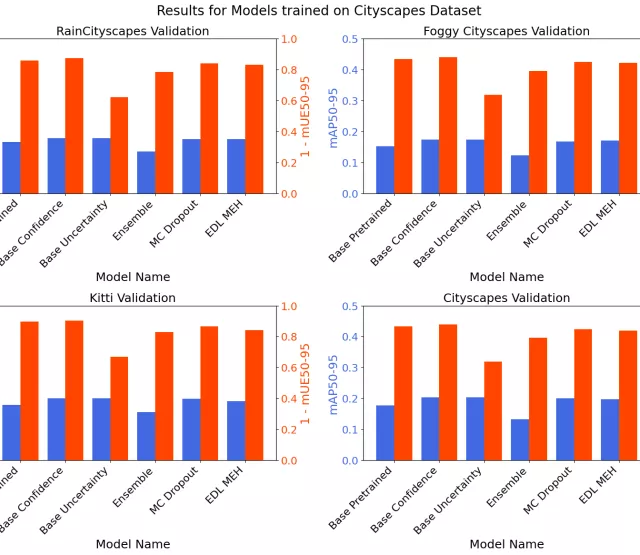
The results are visualized in a series of barplots. For each metric, we indicate whether higher values are better (↑) or lower values are better (↓). Additionally, we highlight the best-performing approach per evaluation with green and the worst with red.
Object Detection Performance
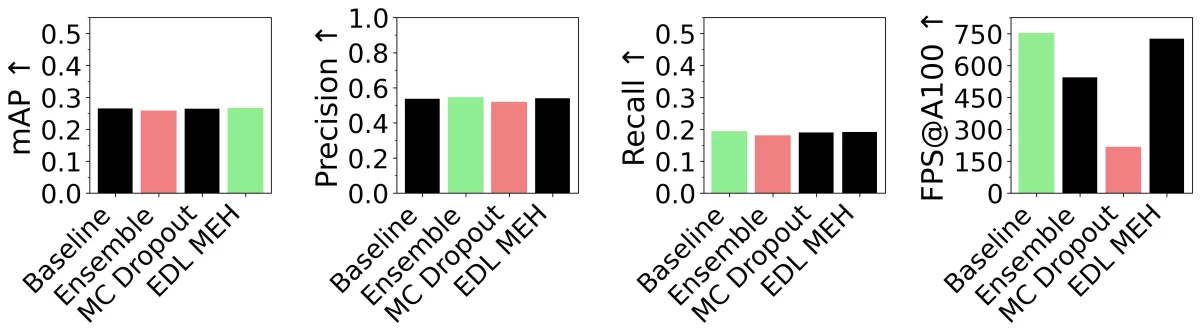
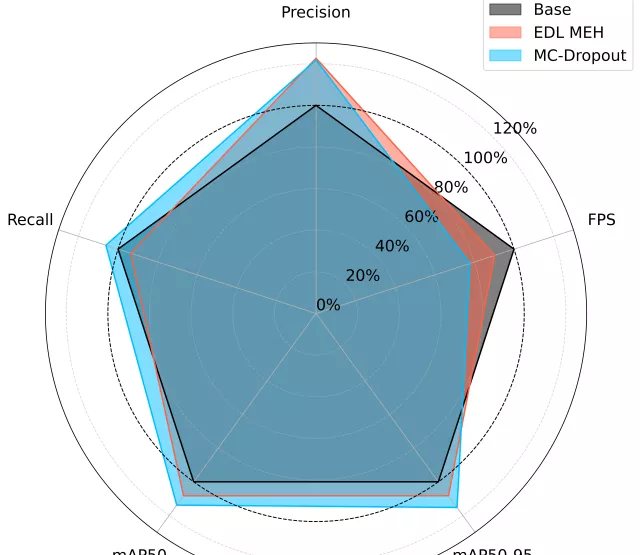
Summarizing results at a high level, the performance of mAP, precision, and recall is nearly the same for all approaches. However, the framerate (FPS@A100) shows significant differences. The baseline achieves around 750 FPS on the NVIDIA A100 GPU, with the EDL MEH approach closely behind. Ensemble frops farther below 600 FPS, and MC Dropout shows the slowest performance by far, only hovering around 200 FPS.
Uncertainty Estimation Quality
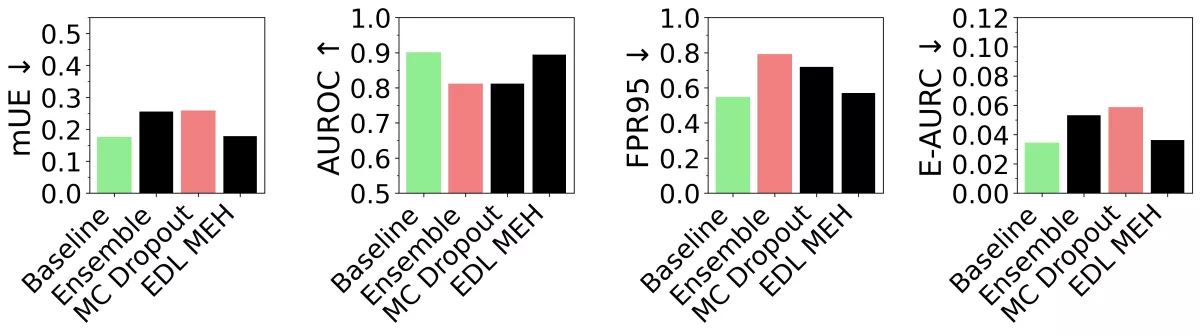
At first glance, it is evident that across all metrics, the Baseline approach is superior. Only EDL MEH can keep up closely, but it still falls short. Ensemble and MC Dropout exhibit similar, yet significantly worse, uncertainty estimation compared to the other two approaches.
Inference Time Analysis
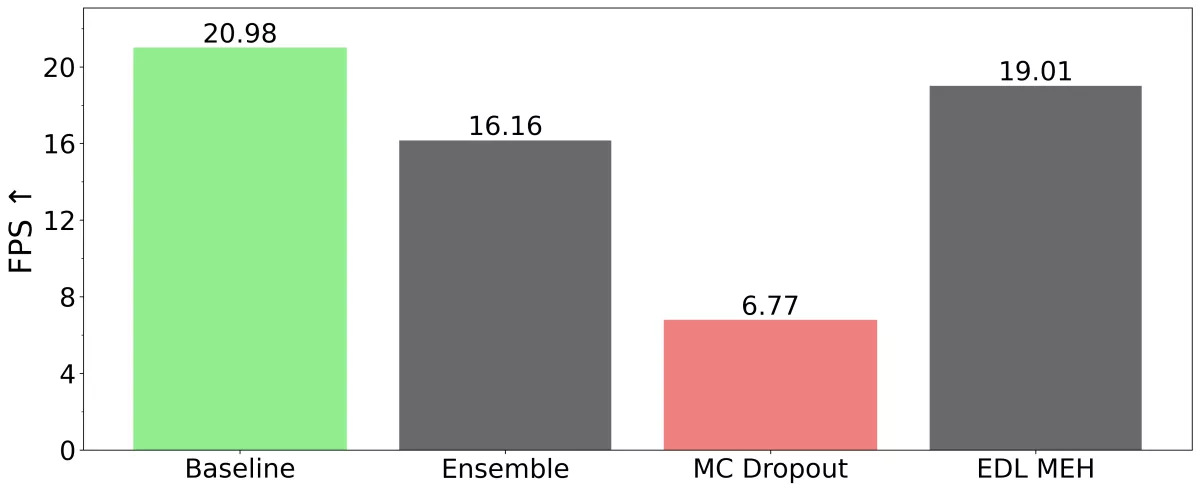
Since having a powerful GPU on the Edge is not a common assumption, we report the performance of our models when run purely on a CPU (AMD EPYC 9354P). Here, we see the baseline at around 21 FPS, which is close to real-time performance. EDL MEH is only 2 FPS slower at 19 FPS. Ensemble runs at 16 FPS, which is 5 FPS slower than the Baseline. The slowest approach is MC Dropout, which achieves a frame rate of less than 7 FPS, rendering it non-real-time capable in this setting.
Conclusion
The simplest approach, viewing uncertainty as 1-confidence (Baseline), outperforms all other, more sophisticated uncertainty estimation methods. Therefore, no positive recommendations can be made for Ensemble, MC Dropout, and EDL MEH when applied in our domain shift evaluation setup, as they provide worse uncertainty estimation at lower frame rates. Sticking to the base detector is the best choice here, regarding trustworthy and fast predictions. Still, EDL MEH shows very similar performance, and with further investigation, it may be able to outperform the Baseline.
References
[1] Glenn Jocher and Jing Qiu. Ultralytics YOLO11, 2024. tex.orcid: 0000-0001-5950-6979, 0000-0002-7603-6750, 0000-0003-3783-7069.
[2] Matias Valdenegro-Toro. Deep Sub-Ensembles for Fast Uncertainty Estimation in Image Classification, November 2019. arXiv:1910.08168 [cs].
[3] Sai Harsha Yelleni, Deepshikha Kumari, Srijith P.K., and Krishna Mohan C. Monte Carlo DropBlock for modeling uncertainty in object detection. Pattern Recognition, 146:110003, February 2024.
[4] Younghyun Park, Wonjeong Choi, Soyeong Kim, Dong-Jun Han, and Jaekyun Moon. Active learning for object detection with evidential deep learning and hierarchical uncertainty aggregation. In The Eleventh International Conference on Learning Representations, 2023.
[5] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The Cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016.
[6] Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? The KITTI vision benchmark suite. In 2012 IEEE Conference on Computer Vision and Pattern Recognition, pages 3354–3361, June 2012. ISSN: 1063-6919.
[7] Christos Sakaridis, Dengxin Dai, and Luc Van Gool. Semantic Foggy Scene Understanding with Synthetic Data. International Journal of Computer Vision, 126(9):973–992, September 2018.
[8] Horia Porav, Valentina-Nicoleta Musat, Tom Bruls, and Paul Newman. Rainy Screens: Collecting Rainy Datasets, Indoors, March 2020. arXiv:2003.04742 [cs].
[9] Fisher Yu, Haofeng Chen, Xin Wang, Wenqi Xian, Yingying Chen, Fangchen Liu, Vashisht Madhavan, and Trevor Darrell. BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning, April 2020. arXiv:1805.04687 [cs].
[10] Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuScenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.
[11] David L. Olson and Dursun Delen. Advanced Data Mining Techniques. Springer Berlin Heidelberg, Berlin, Heidelberg, 2008.
[12] Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The PASCAL Visual Object Classes (VOC) Challenge. International Journal of Computer Vision, 88(2):303–338, 2010. Publisher: Springer.
[13] Dimity Miller, Feras Dayoub, Michael Milford, and Niko Sunderhauf. Evaluating Merging Strategies for Sampling-Based Uncertainty Techniques in Object Detection. In 2019 International Conference on Robotics and Automation (ICRA), pages 2348–2354, Montreal, QC, Canada, May 2019. IEEE.
[14] Jesse Davis and Mark Goadrich. The relationship between Precision-Recall and ROC curves. In Proceedings of the 23rd International Conference on Machine Learning, ICML ’06, pages 233–240, New York, NY, USA, June 2006. Association for Computing Machinery.
[15] Xuefeng Du, Xin Wang, Gabriel Gozum, and Yixuan Li. Unknown-Aware Object Detection: Learning What You Don’t Know from Videos in the Wild. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13668–13678, New Orleans, LA, USA, June 2022. IEEE.
[16] Yonatan Geifman, Guy Uziel, and Ran El-Yaniv. Bias-Reduced Uncertainty Estimation for Deep Neural Classifiers, April 2019. arXiv:1805.08206 [cs].