
Förderjahr 2024 / Projekt Call #19 / ProjektID: 7442 / Projekt: LEO Trek
Gaia addresses a central limitation of current serverless platforms for AI: hardware acceleration is still largely treated as a manual configuration choice instead of a first-class platform concern. As AI workloads move across heterogeneous environments in the 3D Compute Continuum, from edge devices and cloud datacenters to Low Earth Orbit satellites, they increasingly rely on GPUs to satisfy strict latency and throughput SLOs. Contemporary approaches either require developers to statically decide whether a function should run on CPU or GPU, or they perform a single device selection based on a snapshot of conditions. In dynamic settings with workload drift, fluctuating resource availability, and mobility effects such as satellite handovers, these one-time decisions break down and lead either to SLO violations or to inefficient, cost-intensive GPU usage.
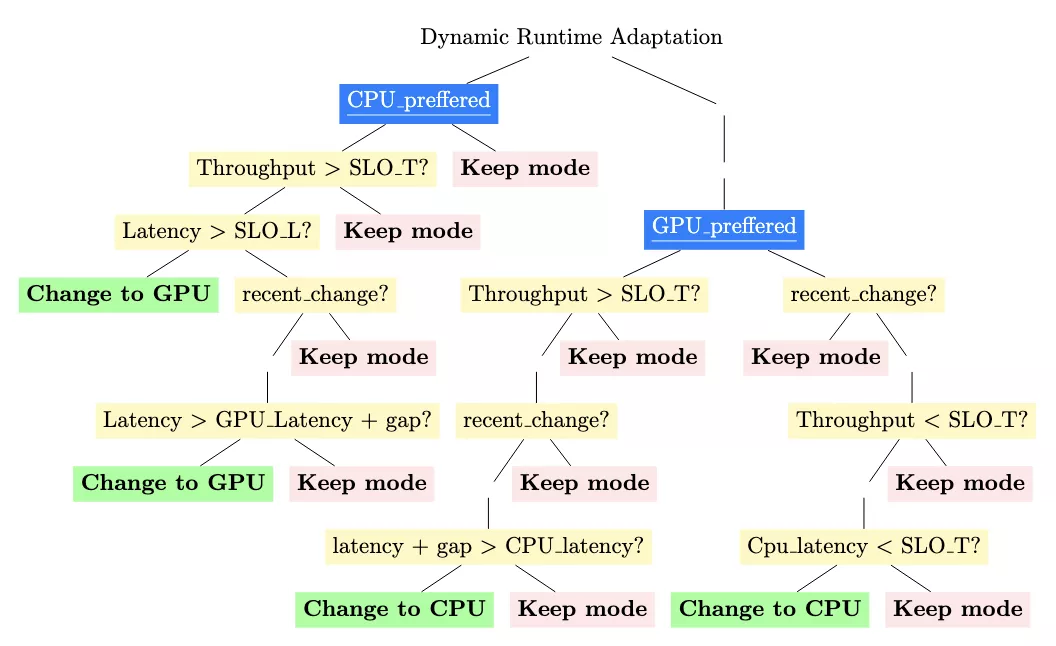
Gaia introduces a GPU-as-a-service model and architecture that shifts device selection from developers to the platform and couples static analysis with continuous runtime adaptation. Conceptually, Gaia provides two complementary mechanisms. The Execution Mode Identifier performs a static inspection of the function code at deployment time. It parses the source into an abstract syntax tree, detects deep learning framework imports such as PyTorch and TensorFlow, identifies explicit GPU calls, and characterizes tensor operations to estimate computational intensity. Based on this analysis, it assigns one of four execution modes, namely cpu, cpu_preferred, gpu_preferred, or gpu, and embeds this classification together with its rationale into the function manifest. This allows the platform to schedule functions onto CPU or GPU capable nodes without requiring code changes or explicit hardware annotations from developers.
The paper evaluates Gaia using a set of representative workloads that capture different AI and non-AI behavior. These include matrix multiplication with increasing input size, image classification with ResNet-18, large language model inference with TinyLlama, and an idle wait function that exhibits high latency without meaningful computation. The experiments are conducted on a heterogeneous MicroK8s cluster with CPU-only and GPU-enabled nodes and executed as Knative services. For matrix multiplication and LLM inference, Gaia initially follows CPU behavior and then, once SLO thresholds are violated, promotes the function to a GPU backend. This promotion yields a step-wise reduction in latency and, due to shorter execution times, reduces monetary costs compared to staying on CPU. For the LLM workload, Gaia and pure GPU mode achieve roughly identical costs and latency once promotion has occurred, while Gaia avoids the initial GPU cold-start penalty. For the idle workload, Gaia briefly promotes to GPU due to high latency, observes no improvement, and then demotes back to CPU, converging to CPU-like cost and performance with only a short and controlled excursion on the GPU. Across the evaluated workloads, Gaia reduces end-to-end latency by up to 95% for GPU-affine tasks while preventing unnecessary acceleration for non-accelerable functions.
By combining a static Execution Mode Identifier with a Dynamic Function Runtime, Gaia demonstrates that hardware acceleration for serverless AI can be expressed as a platform-level abstraction that remains compatible with existing function code and deployment practices. Functions are authored in a hardware-agnostic style, developers can select an automatic mode instead of manually binding to devices, and the platform converges to appropriate CPU or GPU configurations as system and workload conditions evolve. Future extensions of Gaia will focus on predictive, learning-based policies and on workflow-level objectives that coordinate hardware allocation across multiple functions and layers of the 3D Compute Continuum, including LEO-specific constraints such as intermittent connectivity, power budgets, and thermal limitations.
The source code of Lumos is available on GitHub and further details can be found in our paper, which was presented at the IEEE/ACM International Conference on Big Data Computing, Applications and Technologies (BDCAT2025) conference.


