
Förderjahr 2024 / Projekt Call #19 / ProjektID: 7442 / Projekt: LEO Trek
ChunkFunc is a resource optimizer for serverless workflows. It assigns resource profiles to a serverless workflow’s functions to ensure that the response time Service Level Objective (SLO) of the workflow is met, while minimizing costs. Unlike much of the state-of-the-art, ChunkFunc considers the size of the input data of a function when assigning resources. This ensures SLO compliance when the input is larger than average and saves costs when the input is smaller than average. This approach benefits applications with highly diverse input sizes, such as traffic analysis systems. During rush hour, the input to a periodically executed accident detection workflow is larger than average and during night, the input is smaller than average. ChunkFunc’s contributions include:
- An SLO- and input data size-aware function performance model for determining optimized configurations in serverless workflows, depending on the input data size.
- ChunkFunc Profiler, which automatically builds performance models for serverless functions and workflows based on typical input data sizes. Profiling is automatic, users only deploy a function and specify typical input data. A novel, auto-tuned Bayesian Optimization approach reduces the profiling costs by up to 90% compared to exhaustive profiling and ensures high accuracy of the results.
- ChunkFunc Workflow Optimizer, which leverages various heuristics to dynamically adapt the resource configuration of functions in a workflow to meet a performance-based SLO (e.g., response time), while minimizing cost. Depending on the workflow it increases SLO adherence by a factor of 1.12 to 2.0 and reduces costs by up to 53% The Workflow Optimizer is extensible with arbitrary performance-based SLOs.
The ChunkFunc framework consists of two major components: The Profiler and the Workflow Optimizer. The Figure below presents an overview of ChunkFunc and the lifecycle of a serverless workflow within the system. Upon their deployment, serverless functions are automatically picked up by the ChunkFunc Profiler. It deploys function instances using various resource configurations to execute profiling runs with their typical input data sizes, without any user interaction. To reduce the number of profiling runs, while maintaining a high accuracy of the results, the choice of resource configurations is guided by Bayesian Optimization. Our BO Dynamic Hyperparameter Selection picks the hyperparameter that yields the most accurate results for a particular function type and input size combination. Finally, the input-specific performance profiles are leveraged by the ChunkFunc Workflow Optimizer, which provides a suitable resource profile, to meet the workflow’s SLO and minimize cost, to the serverless orchestrator prior to invoking a function.
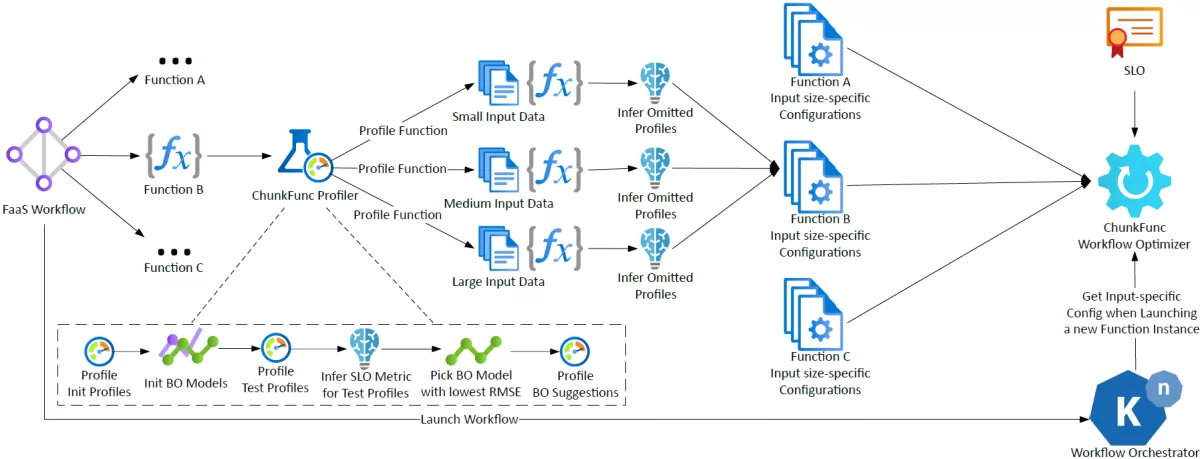
The ChunkFunc Profiler automatically creates input data size-specific performance profiles for every deployed serverless function. The user only needs to specify several typical input data payloads (normally two or three) of different sizes for the function as ChunkFunc-specific metadata. For each defined typical input data size, a distinct performance profile is computed fully automatically by ChunkFunc.
While exhaustively profiling the function under every resource profile is supported, it can incur high costs. Thus, we leverage Bayesian Optimization (BO), which is a technique to find the maximum of an unknown objective function, based on a limited set of samples. It allows for an up to 90% reduction of profiling costs. Common choices for the acquisition function of BO include Probability of Improvement (POI) and Expected Improvement (EI). POI returns the probability that sampling a certain point will yield an improvement, but it may easily result in focusing only on a specific region of the objective function (exploitation) or jump around too much (exploration). EI aims to quantify the improvement and is less prone to the aforementioned issues [8]. In ChunkFunc we rely on both: we use EI to determine which point, i.e., resource profile p, to profile next and POI to define the stopping criterion. Since EI yields an absolute value and POI a percentage, the latter is more suitable as a stopping criterion.
Our aim is to achieve a relative root mean square error (RMSE) of 10% or less when comparing the BO-guided profiling results for an input data size to exhaustive profiling results to ensure that the inferred profiling results adequately reflect the actual performance. We use two stopping criteria for BO: i) the POI for sampling the next resource profile is below 2%, provided that we have sampled at least 10% of the available resource profiles, or ii) we have sampled 40% of the available resource profiles. Based on our experience it is necessary to sample at least 10% of all resource profiles, because for some functions the POI is already below 2% after the initial samples, but the relative RMSE would be above 10%. The second stopping criterion is necessary, because for some functions the POI does not drop below 2%, even though the RMSE is already sufficiently low.
Each input data size |x| is profiled independently with a distinct BO model. Once a stopping criterion is fulfilled, the performance profile of the function with the input data size |x| is built. For each resource profile the profiler takes either the mean SLO metric that was measured, if the resource profile has been evaluated, or uses the Gaussian Process (GP) to infer the SLO metric.
ChunkFunc Workflow Optimizer leverages the performance profiles to assign resource profiles to each individual function instance in a workflow, based on the input data sizes, while fulfilling the SLO and minimizing cost. The SLO serves as an upper or lower bound for the aggregated SLO metric of the entire workflow, while the total cost should be minimized. Since the set of function inputs is filled step by step as the workflow executes, we need a heuristic to approximate the solution of the ChunkFunc optimization problem as the workflow progresses.
Before executing a function, the workflow orchestrator queries the Workflow Optimizer for the resource profile. Akin to the optimization problem, the Workflow Optimizer models the workflow as a DAG. To determine the resource profile for a function, the Workflow Optimizer needs its input data size. The heuristic receives as input the workflow graph, the SLO, the input data size for the current function, and the SLO metric value for the current execution path. Since the heuristic is invoked for each node, while the workflow is executing, it can react if previous functions affected the SLO metric differently than expected, e.g., they took more time than expected. Details on ChunkFunc’s heuristic are provided in the respective academic publication.
All details about ChunkFunc are available in the respective publication and the source code is published on GitHub.


