
Förderjahr 2021 / Stipendien Call #16 / ProjektID: 5900 / Projekt: Synthetic Content for Probe-Resistant Proxies
So what am I working on actually?
The inspiration for this work originated from a discussion thread inside the Tor Project's Gitlab instance and is based on the work from Frolov and Wustrow named "HTTPT: A Probe-Resistant Proxy". In their work they describe the idea of a proxy that hides behind an HTTP server and can resist active active probing attacks. The discussion thread was about finding a way to programmatically create content (therefore synthetic content) for the web server that should serve as a camouflage for the hidden proxy. The easiest approach would be to simply copy the structure and content of an already existing website, but this would not only cause legal issues (copyright claims) but also raise suspicion if a censor would inspect the web server and find copied content on it.
Probe-Resistant Proxies
As the name already indicates, a probe-resistant proxy represents a proxy that is not vulnerable to active probing attacks. During these attacks the censor would try to connect to the suspected server and attempt to communicate with it using several known circumvention protocols. If the server responds to one of the protocols, it reveals itself as a proxy and the censor will block access to that server.
In order to resist these attacks several probe-resistant proxy protocols have been developed, including ScrambleSuit, obfs4, Shadowsocks and Lampshade. These protocols have one thing in common, they require the knowledge of a shared secret in order to establish a successful connection with the server. The secret is shared with the clients through a private channel beforehand. Active probing attacks are for example performed by China's great firewall, in which they send connection attempts to suspected Tor servers. Random data is being generated to guess the correct secret and if the server responds with the Tor protocol it will be blocked instantly.
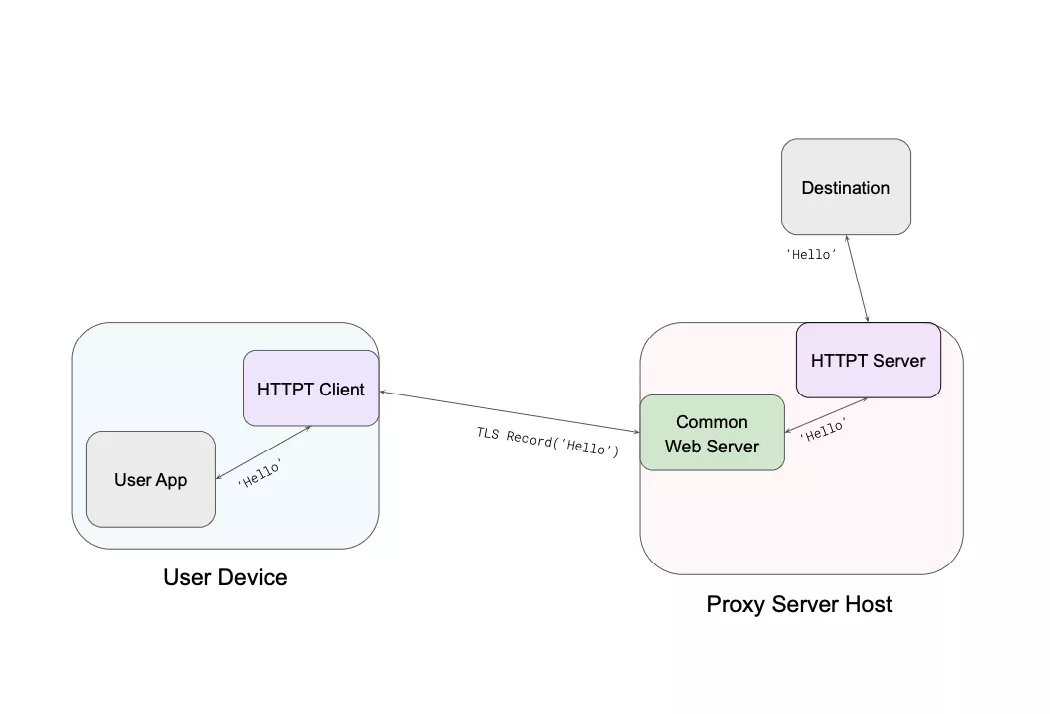
This diagram gives a brief overview of the basic concept of HTTPT. The user, located in a censored network, would install the HTTPT client and provide the secret that was obtained beforehand through a channel like email or telegram for example. The HTTPT client will establish a successful TLS connection to the web server that disguises itself as a harmless HTTP web server to the censor, but equipped with the correct secret, it will allow the HTTPT client to connect to the proxy that is located outside the censor controlled network and hidden behind a HTTP server, and allow the user to access content that might otherwise be blocked.
Synthetic Content
The aim of this project is to create a framework capable of automatically creating a complete website from scratch with as less effort as possible from a user perspective, to mask the true intentions of the HTTP server as well as possible. This includes the website's DOM structure as well as the content served on the website (textual content as well as images) without violating copyright laws.
Website Templates
During the first step, the framework offers a collection of open source Jekyll templates to choose from, which have been collected from Github. Jekyll is a static site generator written in Ruby that only takes Markdown, Liquid, HTML and CSS as input. The advantage of using a static website is that the there is no processing of the content on the server, therefore no interaction with databases is needed, which reduces the website generation complexity. The framework parses those templates and adds placeholders to every webpage which will be filled with texts and images during the next stages.
Text and Images
There are a number of language models to choose from that offer text generation capabilities. However, most of them require the user to setup the model, which would require machines that fulfill the high demanding resources which subsequently can carry immense costs. Luckily, OpenAI offers an effortless approach to accessing these models by providing an official API. Although access to the API is not for free, OpenAI offers upon request free credit's for research purposes. The framework will use this API access to generate its content.
GPT-3 is OpenAI's most capable language model and it provides several engines to choose from, depending on the actual task and the required speed for it. Additionally, it offers a content filter option, which comes in handy, since the framework needs to create synthetic content that won't automatically trigger a censor to block the website just based on the topics covered within the website.
Dall·E 2 is an AI system from OpenAI that can create realistic images from a description in natural languages. This will help our framework to add images meaningful images to the synthetic content and increases the actual authenticity of the website. Unlike GPT-3, access to Dall·E 2 is only possible through joining a waitlist.
Current Development Status
As of writing this blog article, the framework is capable of parsing the Jekyll templates and positioning the placeholders inside the documents. After some waiting, API access to GPT-3 has been granted and development of generating and placing the synthetic text content has started. However, it is still uncertain when and if access to Dall·E 2 will be granted within a feasible time. If not, alternatives have already been selected and will be otherwise further researched on.




