Building Knowledge Graphs for Under Resourced Languages
Förderjahr 2024 / Stipendium Call #19 / Stipendien ID: 7335
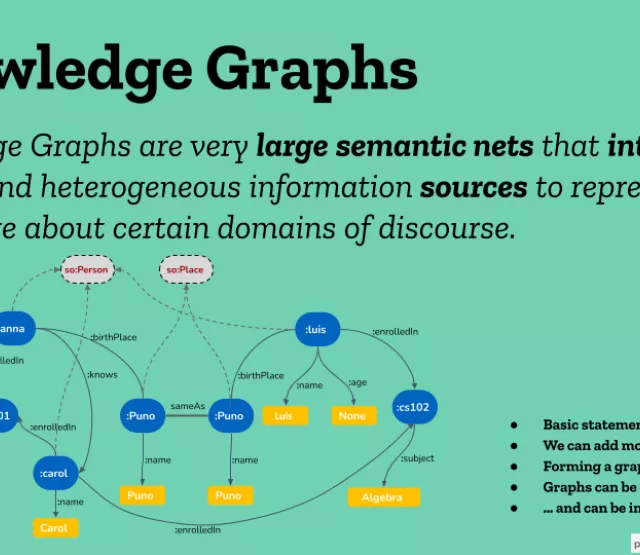
This work aims to lay the foundations for building community-centred and language-aligned Knowledge Graphs for Under-Resourced Languages and their communities. These Knowledge Graphs will act as a common sense layer and will play a key role in shaping the Internet and Artificial Intelligence applications for a better future, where no one is left behind. Why this project matters: There are about 7000 languages in the world and only a few of them have been implemented in language technologies. How it is done: Allowing all languages to be represented in knowledge graphs Contributions: A community-driven approach to knowledge graph curation, and bringing awareness of bias in knowledge graphs and AI applications.
Uni | FH [Universität]
Themengebiet
Zielgruppe
Gesamtklassifikation
Technologie

Projektergebnisse
Building Knowledge Graphs for Under-Resourced Languages Interim Report
Huaman, E., Huaman, J. L., Huaman, W., & Quispe, N. (2025). Quechua speech datasets in common voice: The case of Puno Quechua. In *Information management and big data – 12th annual international conference (SIMBig 2025), Lima, Peru, October 29-31, 2025, Proceedings. Springer.
This datasheet is for version 2.0 of the the Mozilla Common Voice Spontaneous Speech dataset for Puno Quechua (qxp). The dataset contains 2211 clips representing 10 hours of recorded speech (6 hours validated) from 26 speakers.
This datasheet is for version 24.0 of the the Mozilla Common Voice Scripted Speech dataset for Puno Quechua (qxp). The dataset contains 9033 clips representing 11.63 hours of recorded speech (9.88 hours validated) from 14 speakers.
I act as part of the advisory committee for the Shared Task: Mozilla Common Voice Spontaneous Speech ASR, that challenges researchers and developers to push ASR further, across 21 underrepresented languages from Africa, Asia, Europe and the Americas.
Final report that describes the current status and next steps.