
Förderjahr 2022 / Projekt Call #17 / ProjektID: 6252 / Projekt: CrOSSD
As it has been quite some time since our first blog post, which introduced our envisioned system architecture, we want to give you a look at our current system.
CrOSSD Cluster
Behold, here is our revised system architecture:
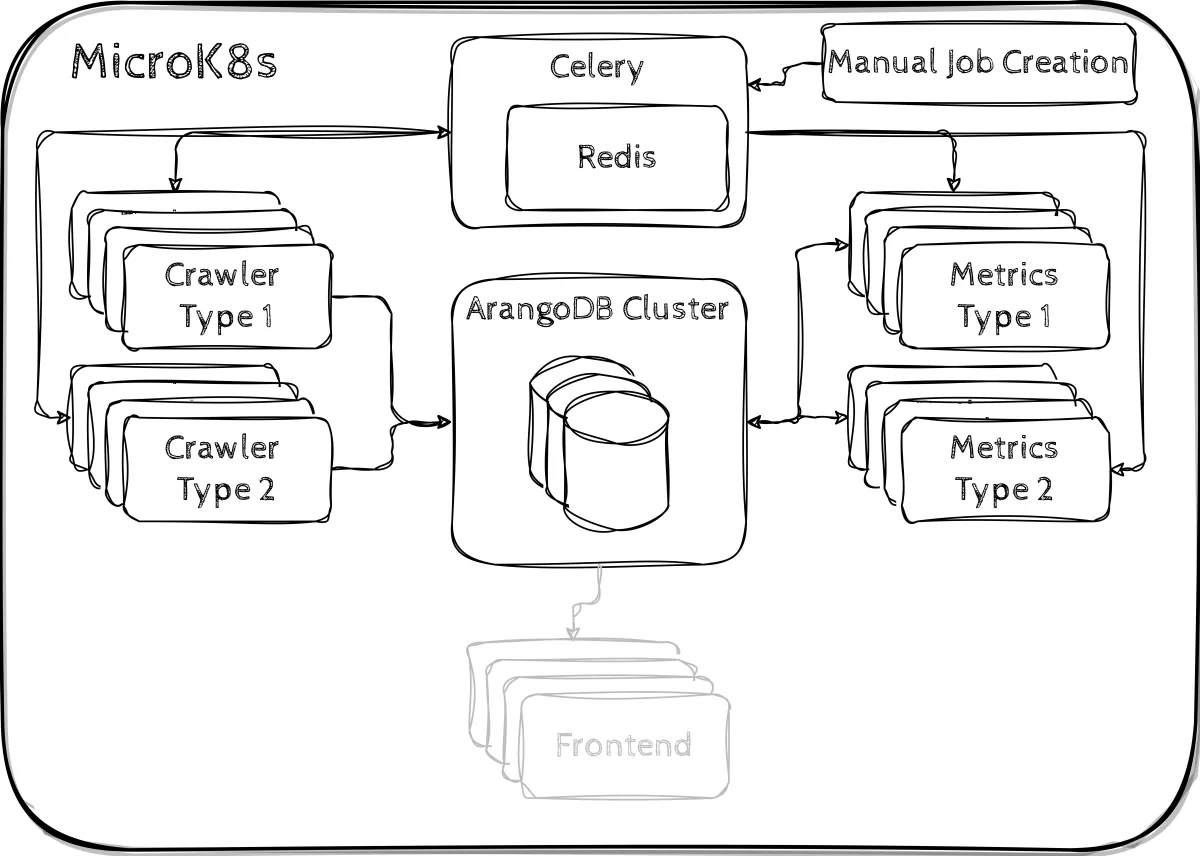
Kubernetes Cluster
As we wanted to ensure the scalability of our system, we decided to implement our system as a Kubernetes cluster.
Why Kubernetes instead of e. g. Docker Swarm?
We want our system to be used by a lot of people and also enable companies to host our system themselves. We have the impression that more companies use Kubernetes and there are more cloud services providing the possibility to deploy a Kubernetes cluster, hence why we chose it.
Would this work with Docker Swarm as well?
As the components are just Docker Containers, they can essentially work with any container orchestration framework. You would need to create a custom Docker Compose file for configuration of the containers and the swarm.
Task Queue
The Python package Celery serves as our distributed task queue along with a Redis broker. There are task for the repositories we want to crawl which are scheduled and assigned to workers by Celery.
Crawlers
The crawling is done via different crawlers. Currently, there are two different types. Crawler type 1 mostly utilises the GitHub REST API to gather information and uses the library developed by Jacqueline Schmatz during her diploma thesis. Crawler type 2 is largely built around the GitHub GraphQL interface. The crawlers store the collected data inside our database and trigger the components calculating the metrics.
ArangoDB
We chose ArangoDB for storing our data as it already supports a distributed deployment via Kubernetes and provides the possibility to store data using different data models such as document, key-value or graphs. Our database stores the collected information about repositories as well as the calculated metrics.
Metrics
Just like the Crawlers, there can be various types of metric-calculating containers. Currently there are two types that complement their corresponding crawlers. The calculated metrics are in turn stored inside our database.
Our next step
As our backend is more or less stable (although there is surely going to be some bug fixing in the next months), we will now focus on creating our web interface for presenting the metrics.
That's all for now, stay tuned for our next update! :)

