
Förderjahr 2021 / Projekt Call #16 / ProjektID: 5899 / Projekt: PrototAIp
In December this year, we launched a first version of PrototAIp internally on our server. PrototAIp is now open for our employees, so that they can use it and help us evaluate potential future features. In the following, we describe the architecture and technology stack behind it.
The Usage of JupyterHub
As mentioned in a previous blog post, we selected Jupyter Notebooks as the programming environment for PrototAIp, simply because it is one of the most mature and widely used programming environments in data science, and, additionally, comes with an open-source licence. Lucky for us, Project Jupyter also provides the server solution “JupyterHub” which is capable of handling large amounts of users and can be scaled up if required. It is also open source, which means that we can customize it to the requirements of the PrototAIp project. The hub solution combines an admin and database system with authentication in order to spawn new notebooks for users (see Figure 1). Using such an existing tool was a logical choice, as it allowed us to avoid “re-inventing the wheel” and gives us a robust and stable platform for our users.
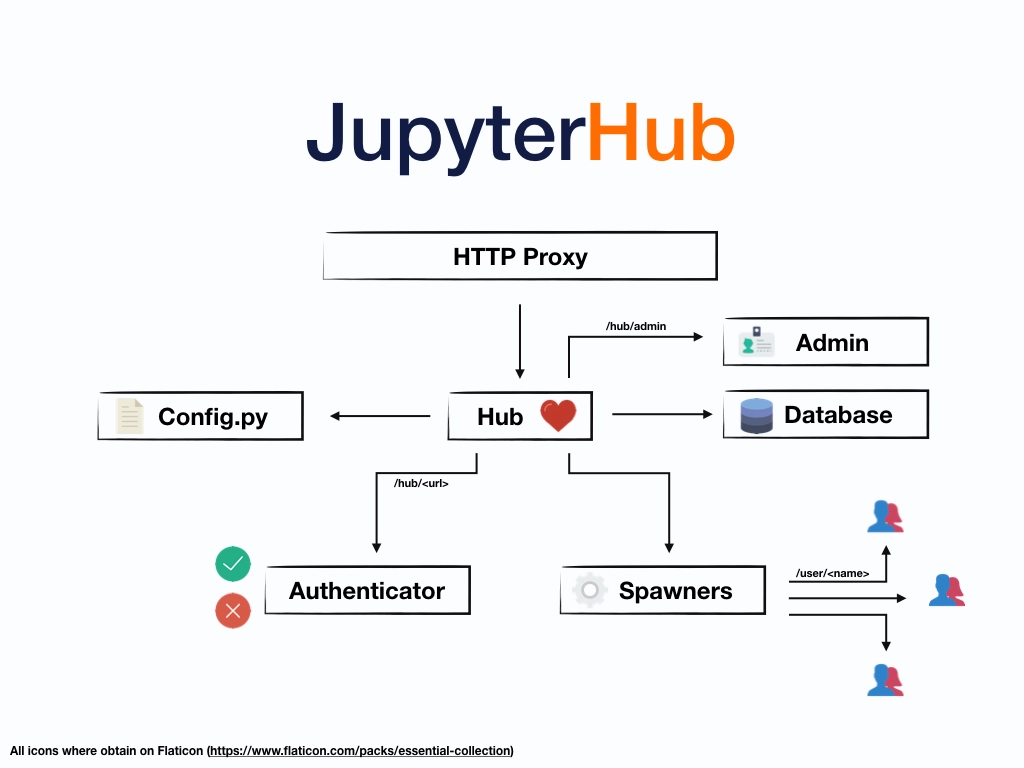
Figure 1. The architecture of JupyterHub.
The Installation
There are three flavors of JupyterHub available: (i) JupyterHub installed via package manager, useful for local installations and testing purposes, (ii) “The Littlest JupyterHub”, a server version suitable for 0 - 100 users, and (iii) “Zero to JupyterHub” (Z2JH), a container-based solution using Kubernetes that can be scaled up to any number of users. We selected the latter version. It is more complicated during installation and setup, but can be scaled easier in case PrototAIp reaches a larger customer base.
An Austrian Solution
PrototAIp is supposed to be an Austrian solution, living on Austrian servers (data being located on servers in e.g. the United States are often a reason for companies not using such solutions). Thus, we used the installation type “Kubernetes on a Bare Metal Host with MicroK8s” instead of a cloud-based installation. This way of installation uses Kubernetes for container orchestration and Helm as a package manager, which helps to install the Z2JH provided by Jupyter.
We installed PrototAIp on a powerful desktop computer, which is fine for our current status. Later, in case PrototAIp attracts more users, we will move to a more robust server solution.
PrototAIp Customization
We have added a little customization to the original JupyterHub interface of PrototAIp and exchanged the out-of-the-box authenticator with an authenticator that allows users to create their own accounts. Furthermore, we use our own prototAIp-notebook (we have a Github and a DockerHub version, if you want to try it out). It has a lot more data-science libraries installed than the default Jupyter Notebook provided by JupyterHub. The prototAIp-notebook was described in a previous post. We will continuously extend it with new libraries, so that data scientists always have the latest and most relevant libraries at hand. At the beginning of the project, we conducted a survey to better understand the software needs of data scientists, whose results are described in this blog post.

Figure 2. The welcome screen of PrototAIp.


