
Förderjahr 2018 / Stipendien Call #13 / ProjektID: 3793 / Projekt: Data Management Strategies for Near Real-Time Edge Analytics
Regarding three aspects of elastic storage, namely, edge data/system characterization, application context and edging operations, we present seven principles as guidelines for engineering elastic edge storage services.
P1: Define and Provide Needed Metrics. To enable efficient customization and adaptation among elements of edge storage systems, it requires a clear definition and flexible monitoring of end-to-end metrics regarding data workloads, application context and system activities.
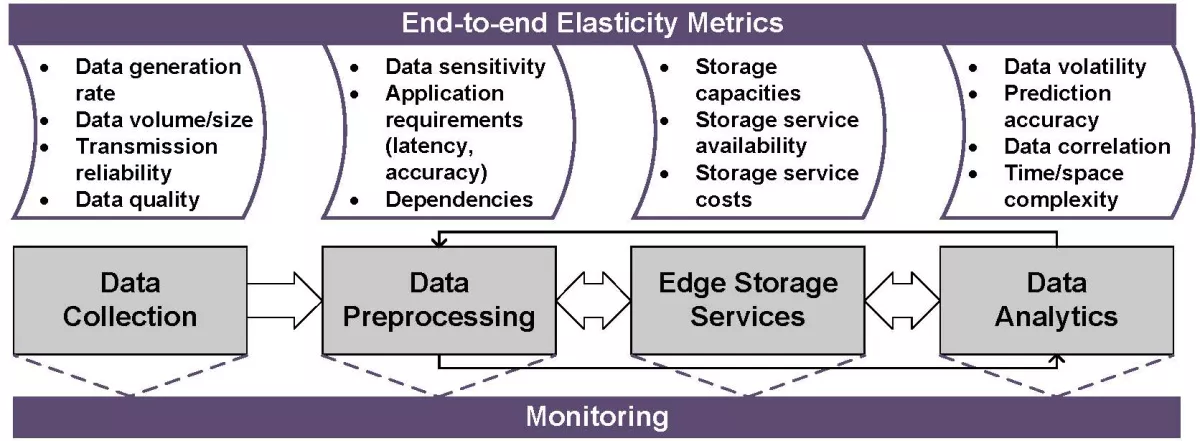
- Method: Figure 1 shows end-to-end monitoring metrics that can assist in elastic edge storage management. There are metrics present in four stages of data life cycle, namely data collection, data preprocessing, storage service analysis and data analytics.
P2: Support Application-Specific Requirements. Based on sensor-specific metrics and relevancy, we can combine different solutions to deliver appropriate data to local analytics, while meeting application conditions, e.g., clean, complete or normalize sensor data before storage and analysis.
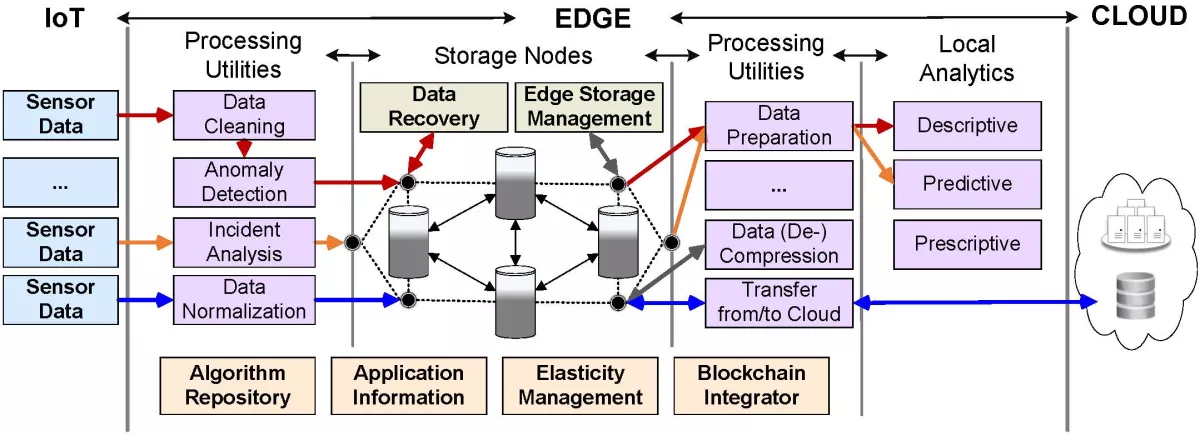
- Method: Figure 2 shows, depending on application information, that different sensor data have corresponding data flow routed through the edge architecture to appropriate edge analytics. Interconnected storage nodes, with features including data recovery and edge storage management, ensure access to the relevant data at the right time for different purposes. An algorithm repository contains a set of predefined processing utilities, which usage and order are application-specific and dynamically set at runtime in the elasticity management component, while blockchain integrator can capture certain types of application-specific data and pass them to the edge blockchain network for verification and auditing.
P3: Enable Adaptive Data Handling. From a software management standpoint, it is necessary to cope with heterogeneous data workloads including dynamic data streams, batch transfers, QoS critical requirements. Storage service should ensure that stored data are always available, relevant and complete.
- Method: In this context, critical software technology running on the edge can play an important role in storage resources abstraction, supporting communications, configuring suitable data handling features and on-demand data transfers.
P4: Highly Customized System Bundling. Edge storage features should be highly customized and application aware. Considering data workloads and deployment conditions, traditional inflexibility in software modules bundling can produce over- or under-bundled features for supporting edge application analytics. Thus, flexible storage configurations need to meet deployment situations.
- Method: Based on application-specific information and internal constraints (capacities, resources), the build and deployment process should bundle only components to match these constraints for the right infrastructures.
P5: Runtime Software-Defined Customization. Different inputs, such as application information and data workload characteristics, must be combined to support runtime customization of elastic operations and data processing utilities.
- Method: To deliver potential control flow for elastic storage services, it requires a loop for managing internal storage system initially taking valid application information and current storage system metrics. Dynamic workload characteristics should be combined with static knowledge (elastic operations and processing utilities). Finally, to decide situational trade-offs for data quality and storage capacities, we need to derive an optimization strategy for customized storage with core software-defined APIs for data management and service operations.
P6: Support IoT-Edge Continuum. This principle looks at impacting constant data flows between IoT systems and edge storage services, while supporting underlying protocols. According to edge storage performances, it requires triggering different actions with changing data generation frequency on-demand.
- Method: Both IoT and edge nodes require developing an edge-IoT connector to control data flows that can often be unpredictable. This connector should be able to (1) discard incoming poor-quality data; (2) apply various sampling commands for collecting only relevant data; (3) trigger actions for turning off/on sensors; highly impacting overall performance of edge storage services.
P7: Support Edge-Cloud Continuum. This principle looks at inter-operation and data transmission between edge and cloud storage systems. Despite the advantages of edge nodes, it is obvious that for many applications, cloud repositories still have to keep large datasets for complex data mining and big data analytics. Thus, we need to support efficient and secure data transfer of large datasets.
- Method: For efficient edge-cloud cooperation we must build an edge connector to the cloud, supporting: (1) operation viewpoint featuring timely techniques for data approximation, (de)compression and encryption/decryption; (2) network viewpoint featuring mechanism to avoid excessive data traffic; (3) analytics viewpoint featuring coordination mechanism for consistent analytics models.





