
Förderjahr 2018 / Stipendien Call #13 / ProjektID: 3793 / Projekt: Data Management Strategies for Near Real-Time Edge Analytics
This blog introduces a use case for self-adaptive placements of data analytics in the edge-cloud environment based on data locality, aiming to efficiently place the analysis where data is located.
Performing data analytics at the edge still requires dealing with issues such as the rapidly growing amount of data, limited storage capacities and high failure probabilities of edge nodes. A rapidly growing amount of data produced at the edge hinders the centralized data collection and performing analytics traditionally. Therefore, datasets nowadays can often reside in different locations from where they were produced initially. Datasets can be moved, migrated or replicated due to
- limited storage capacities;
- edge node failure probabilities;
- meeting certain service level objectives (e.g., availability and resilience to failures);
- workload balancing.
This leads to the difficulty of tracking datasets and deploying analytics to the right locations. Thus, data locality represents one of the critical problems for on-demand analytics placement at the edge.
This problem can be found in a typical application such as edge video analytics. Video analytics are considered as the killer app for edge computing. Object detection is a popular video analytic workflow in which video frames are analyzed by a model (usually, a neural network) to produce a list of objects with varying degrees of confidence. Figure 1 shows the challenge of tracking a specific video dataset whose location can change at later time points. The motivational scenario illustrates the problem of locating a missing child, that is captured on video frames initially stored at Location A at time 1. However, due to many reasons such as limited storage capacity (time 2) or edge failure probabilities (time 3), the dataset can be migrated and replicated to new locations. Finally, at time 4, the query for detecting and locating a missing child should be deployed on a specific dataset that is not stored anymore in the initial location. The dataset of a specific camera can at different time points be in different locations, preventing users from timely and accurately executing queries.
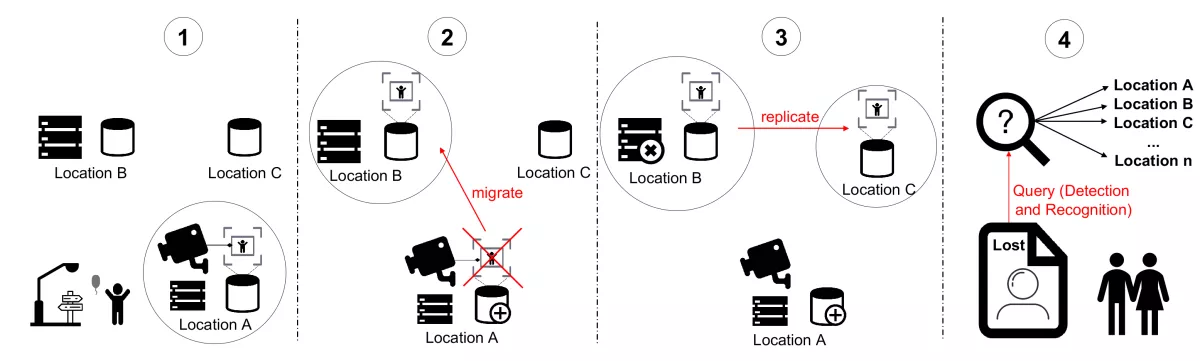
This problem can be found in other event-driven scenarios, such as finding missing pets, locating suspect’s vehicle, fraud analytics, post-crime investigation, failure prevention in smart buildings and smart manufacturing. Making automatic analytics placement to the right locations is one of the crucial factors that significantly impact the critical decision-making.
Many edge nodes (e.g., micro data centers, edge gateways, smart devices) can execute analytics tasks such as object detection in video surveillance, predictive maintenance in smart manufacturing or medical data analysis in eHealth. We want to ensure accurate placement of critical analytics tasks to the right locations, proposing an approach called Self-adaptive Analytics Placement (SAP) based on data locality. The main ideas are: (i) enabling tracking datasets for accurate analytics placement; (ii) allowing on-the-fly adaptation and deployment of the analytics tasks to nodes storing datasets within a single-cluster; (iii) introducing a prototype for using data locality in SAP across a multi-cluster environment such as a hybrid cloud.






