
Förderjahr 2018 / Stipendien Call #13 / ProjektID: 3793 / Projekt: Data Management Strategies for Near Real-Time Edge Analytics
The core element of each IoT application is data. Especially, if there are critical applications such as healthcare, intelligent traffic monitoring or smart buildings, collected data must be accurate, complete and available for decision making.
As shown in one of previous blogs, high failure rate in IoT systems can cause missing values and outliers in collected datasets. This includes network and monitoring system failures leading to potentially deteriorated quality of near real-time decisions. It is highly important to have complete data before their analysis. There are many forecasting techniques that can be employed to predict gaps containing missing values, but due to high volatility and different data behavior it is impossible to define one technique that gives best results (lowest error) for each incomplete dataset that is recovered. Furthermore, relying on edge nodes that are close to IoT data sources, there is no space to keep all historical data that could improve forecast accuracy. In this regard, it would be helpful if we can build a mechanism that recommends most appropriate range of relevant data for recovery of certain gap lengths including an appropriate technique to be applied.
More historical data does not imply better forecast!
On the one hand, performing analytics on incomplete/invalid datasets can lead to inaccurate results and imprecise decisions. On the other hand, while relying on resource-constrained edge nodes, we cannot store all historical data that could improve forecasting process. Storage space limitations prevent us from storing all the measurements collected by edge systems. However, I argue that more historical data does not imply better forecast, especially if we consider unpredictable lengths of appeared gaps.
Single-technique Recovery (STR) vs Multiple-technique Recovery (MTR)
Let us consider two possible scenarios, namely: (1) single-technique recovery (STR) and (2) multiple-technique recovery (MTR). In the first scenario, a single technique, that can be specified by users, is used for recovering all detected gaps in collected dataset. In the latter scenario, a technique selection is performed for different gap lengths (containing different amount of missing values).
Single-technique recovery
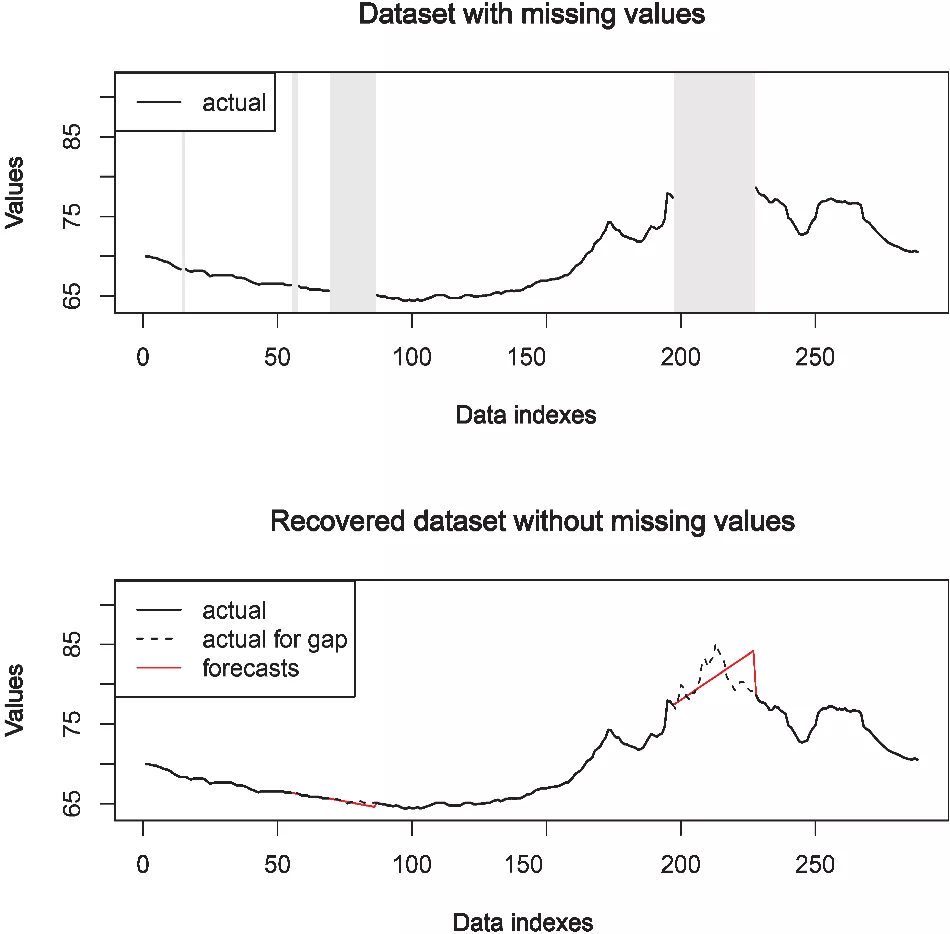
Figure 1 shows simulation with dataset containing gaps and dataset after performed data recovery using STR approach. The upper graph shows an incomplete subset of the dataset before the recovery, while the lower graph shows a complete dataset after recovery. Gray shaded areas indicate four gaps. The black dashed line shows actual data for corresponding gaps, while the red solid line represents predicted values of missing/invalid data as an output of applied forecasting techniques. In this case, multiple gaps are automatically recovered using AutoRegressive Integrated Moving Average (ARIMA). Although, there are many techniques available, one of the widely used forecasting techniques includes ARIMA and Exponential Smoothing (ETS). Further, it can be seen, as the gap increases, the forecasting error increases as well. In order to efficiently recover all gaps, multiple techniques could be involved in recovery process of each gap separately, that is, the MTR scenario.
Multiple-technique recovery with Projection Recovery Maps (PRMs)
To automatically recover incomplete sensor-based time series, we should ensure self-adaptive recovery of each gap separately. One approach to the solution can employ a mediator component (See proposed EDMFrame architecture in the previous blog) that detects an optimal trade-off between the gap size and a necessary range of historical data by managing PRMs for each dataset. In addition, it can recommend which method is most appropriate regarding high forecast accuracy.
Figure 2 illustrates representative example of PRM for one dataset. The colors of the bold line at the bottom shows the selected method, that is, yellow for ETS and gray for ARIMA. For each selected range of required data points, MAPA value is shown with an orange line. Building the PRM requires more historical data, therefore it can be built only in the cloud. For this reason, the mediator component can store only final PRMs. When a gap is detected by the monitoring component, the mediator recommends range of required data points for recovery and an appropriate forecasting method. In case there is not enough data in edge storage, mediator component can require certain amount of data from the cloud repository and temporarily store them for the data recovery process.
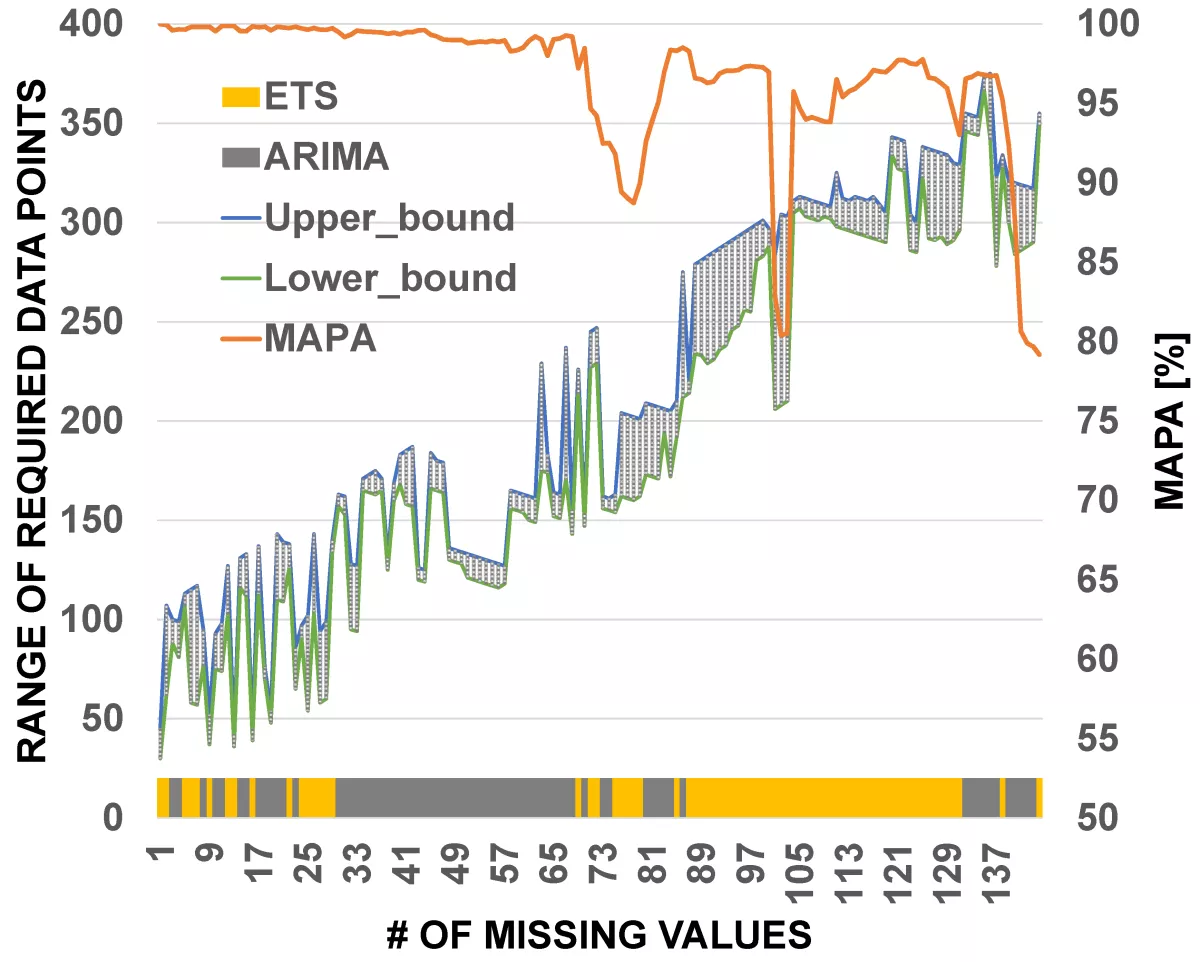
Accordingly, analytics can be executed in the cloud using historical data and then resulted PRM is sent to the mediator component. Selecting an appropriate range, means selecting a range of data that gave the highest forecast accuracy in offline experiments. One challenge is remaining: how to incorporate scalability and elasticity of these approaches in designing future edge data management framework as well as efficient connections with IoT and cloud.





