
Förderjahr 2018 / Stipendien Call #13 / ProjektID: 3793 / Projekt: Data Management Strategies for Near Real-Time Edge Analytics
Cloud computing offers dynamic and powerful resources, but the response time might suffer due to the high latency. Processing data at the network edge can reduce latency, but it lacks scalable resources and includes potential incomplete data.
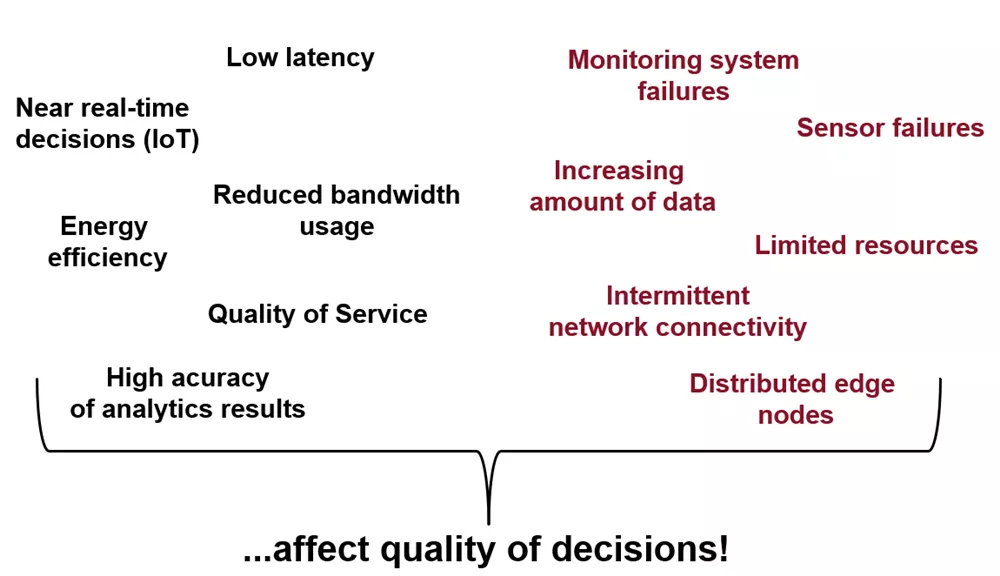
Emerging challenges from the edge layer
Miniaturizing hardware to fit on small scale systems, such as micro data centers, requires novel edge data management approaches while dealing with emerging IoT requirements. Critical applications like eHealth, smart grids or intelligent traffic systems must process huge amounts of data with strict accuracy and latency requirements.
Performing data processing in edge nodes, allows making needed near real-time decisions for IoT systems. At the same time, utilizing edge nodes raises several challenges: first, missing values and outliers may appear in data collected by sensors. Performing analytics on incomplete data can cause problems in different contexts, leading to inaccurate results. Incomplete data can occur for different reasons, for example, (1) the highly distributed nature of IoT systems; (2) monitoring system failures; (3) data packet loss in sensor networks; (4) intermittent network connectivity; (5) changes in external conditions; or (6) sensor failures [1], affecting both near real-time and batch analytics. Second, edge nodes have limited storage and they are not scalable as cloud centers. Such limitations can hinder accuracy of edge analytics and consequently decisions for critical applications such as smart buildings and cities [2].
Figure 1 represents the requirements of edge deployed systems (left side) and limitations (right side) that can affect quality of decision-making processes at the edge of the network.
Sensor-based time series data
Among different types of IoT sensor-based data, time series data are typical in IoT systems. A time series represent a sequence of data points made over a continuous time interval, where each data point consists of a time stamp and one or multiple values. Time series can be collected from systems having either equal or unequal monitoring time intervals between data points. In the first case, for example, they are made by periodically reading outdoor temperature. In the second case, they can occur, for example, when data generation is triggered by certain events like in monitoring changes of patient’s state of health.
Necessary methodologies for novel data management strategies
- While cloud computing offers dynamic and scalable resources, edge computing pushes data processing to the edge of the network, in proximity of data sources. Hence, edge computing, as an emerging methodology, improves cloud computing systems by reducing communication bandwidth and latency for IoT deployed systems.
- Further, statistic measurements are fundamental, particularly when utilizing sensor-based time series data. For that purpose, pattern recognition, especially for seasonality detection, and various features such as mean, variance and standard deviation, can be applied. For example, to choose appropriate forecasting methods in predictive analytics, it is necessary to explore data characteristics such as data stationarity and non-stationarity.
- Forecasting methods rely on statistical learning. There are several most widely used forecasting methods appropriate for this research, namely, Autoregressive Integrated Moving Average (ARIMA) and ExponenTial Smoothing (ETS). ARIMA can be used if data contain stationary characteristics, such as trend stationarity, while ETS, although overlapping in same cases with ARIMA models, can be used for short-term seasonal series or with multiple complex seasonality. Based on characteristics of historical data, they obtain different patterns, estimate needed parameters and automatically compute suitable forecasts. Therefore, since we are faced with near real-time decisions, these techniques can be suitable for edge predictive analytics.
- To achieve certain goals such as distributed and in-transit data analytics, it is necessary to investigate other methodologies such as data mining and machine learning approaches. Edge predictive analytics might require novel approaches, especially when underlying system processes are typically nonlinear and non-stationary as in distributed IoT system.
It can be seen that many applications can benefit from edge computing, but existing solutions are usually not scalable or validated for edge layer, leaving many research issues for novel data management strategies.
References:
[1] Aggarwal, Charu C., Naveen Ashish, and Amit Sheth. "The internet of things: A survey from the data-centric perspective." Managing and mining sensor data. Springer, Boston, MA, 2013. 383-428.
[2] Lujic, Ivan, Vincenzo De Maio, and Ivona Brandic. "Adaptive Recovery of Incomplete Datasets for Edge Analytics." Fog and Edge Computing (ICFEC), 2018 IEEE 2nd International Conference on. IEEE, 2018.






