
Förderjahr 2018 / Stipendien Call #13 / ProjektID: 3793 / Projekt: Data Management Strategies for Near Real-Time Edge Analytics
This blog introduces a testbed for experimentally evaluating edge data management strategies, aiming to have a better overview of needed technologies and physical resources.
Following the blog post from December 2019, in this blog post, I give an overview of a testbed setup for experimentation of proposed new concepts as well as for future real-world demonstrations of edge data management strategies. Currently, we are installing a lab where we plan to apply different evaluation strategies and simulations of proposed approaches.
Edge computing should enable adaptive placement of applications across different infrastructures
The edge computing paradigm has been proposed to meet the strict latency and accuracy requirements of modern applications by extending cloud functionalities closer to the source of data. It is possible nowadays to process data closer to its origination thanks to technological and scientific advances that allowed placing compute, network and storage capabilities to edge nodes, micro data centers or resource-constrained devices such as Raspberry Pis. In order to cope with the ever-growing application requirements and user needs, in the near future, we can expect many edge-deployed and distributed clusters managed by different providers as in the multi-cloud concept. The multi-cloud concept has been introduced to run user applications across several hosting environments, eliminating the reliance on specific architecture providers. Similarly, the new edge computing paradigm should ensure adaptive placement of data analytics tasks and application instances across different infrastructures to keep overall system performance under control. Edge-deployed clusters can be heterogeneous containing different initial capacities as well as different availability of resources over a certain period of time.
A set of technologies, tools, and languages should be used to set up a virtual environment for testing proposed strategies, including:
- Kubernetes is a platform, developed by Google, representing one of the widely used open-source orchestrators that automates deployment and management of multiple containerized applications across multiple machines. Kubernetes can be installed with minikube as a single-node cluster running for testing purposes or creating a multi-node cluster on the localhost. Kubernetes is implemented in the Go programming language. Although there are many options, the Kubernetes cluster can be easily created using Vagrant and Ansible.
- Docker is a container platform used to build and isolate applications and corresponding stack of services on containers, that is, standalone execution environments.
- Vagrant represents a tool for managing virtual machine environments. One of the typical provider to set up the virtual machines is VirtualBox. Additionally, Ansible playbooks are used in combination with Vagrant to install needed packages and tools (e.g., Kubernetes, Docker). Ansible playbooks, as later Kubernetes deployment manifest files, are written in YAML (Yet Another Markup Language) as it is often used for configuration files.
A great tutorial on how to set up Kubernetes using Ansible and Vagrant on virtual machines can be found here. Although some EDM strategies are proposed and can be used in this environment, more important challenge is to test them across real infrastructures such as Raspberry PIs or server nodes.
Figures 1 and 2 show the physical architecture on which we plan to simulate novel approaches using 12 Raspberry Pis 3B+ separate into 3 stackable cases, each containing 1 master and 3 worker nodes. Each RPi is equipped with 1 GB RAM memory and a Quad-Core ARM processor running at 1.4 GHz. All RPis are connected to the network with Netgear 24-Port 10-Gigabit Switch and an Ethernet router. Further, we plan to utilize two additional in-house servers (rll-mdc01 and rll-mdc02) equipped with 256 GB RAM memory and 24-core Intel Xeon E5 processor running at 2.2 GHz. Figure 3 shows the installed equipment.
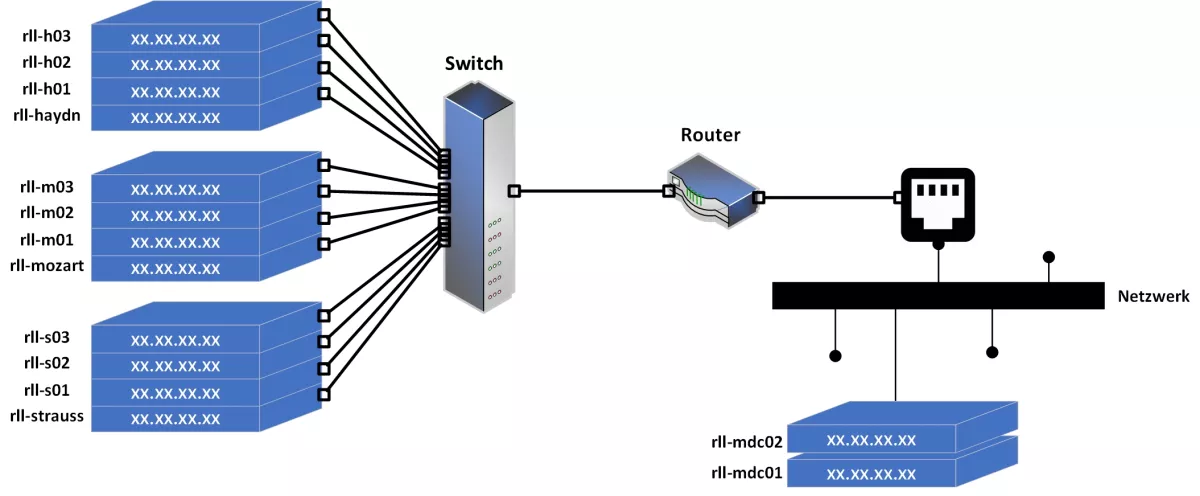

Since the Kubernetes cluster is based on master-worker architecture, Figure 3 illustrates the previous setup in which every cluster consists of three worker nodes and one master node.
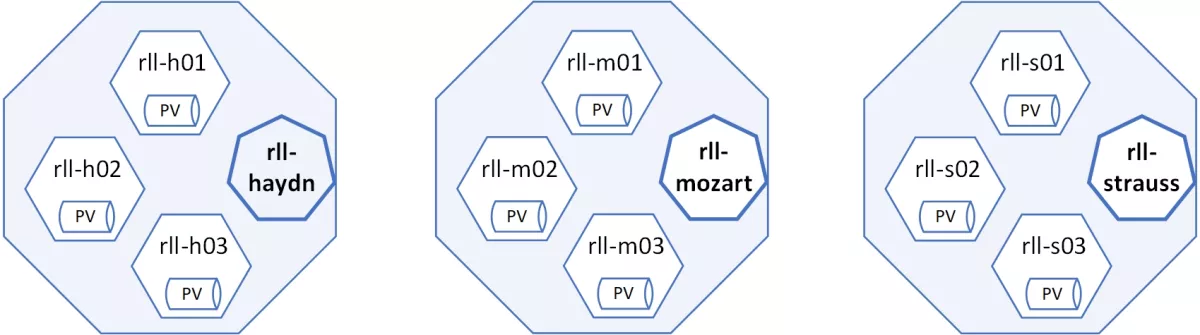
Finally, this testbed will be used for testing adaptive placements of application instances considering data locality and resource requirements. Further, sensor data can be migrated to different locations (e.g., Persistent Volumes – PV) as well as to reside on two or more locations at the same time. The problem is how to automatically place analytics tasks and jobs to different clusters while accessing the right or best data location. In the next steps, the plan is to utilize current equipment to evaluate some of the edge data management strategies as well as for future real-world demonstrations.






