
Förderjahr 2018 / Stipendien Call #13 / ProjektID: 3793 / Projekt: Data Management Strategies for Near Real-Time Edge Analytics
This blog introduces a high-level architecture model overview of the SAPLaw system, aiming to illustrate the main components and steps for achieving self-adaptive analytics placement at the edge.
Regarding the previous blogs, it is possible nowadays to process data closer to its origination thanks to technological and scientific advances that allowed installing compute, network and storage capabilities to edge nodes such as micro data centers or resource-constrained devices such as Raspberry Pis. Edge nodes are often heterogeneous containing different initial capacities as well as different availability of resources over a certain period of time. Therefore, edge computing should ensure adaptive placement of application instances and data analytics tasks across different infrastructures while meeting Service Level Objectives (SLOs) such as resource availability.
Nevertheless, the key advantage of executing data analytics at the edge is the reduction in bandwidth by reducing the amount of data that needs to be directly transferred to the cloud. Since these data are often distributed or placed on different nodes, one of the future fundamental requirements that should be considered in deploying edge data analytics tasks is data locality.
Data locality refers to the concept of processing data at the corresponding dataset locations, instead of moving data to the centralized processing locations.
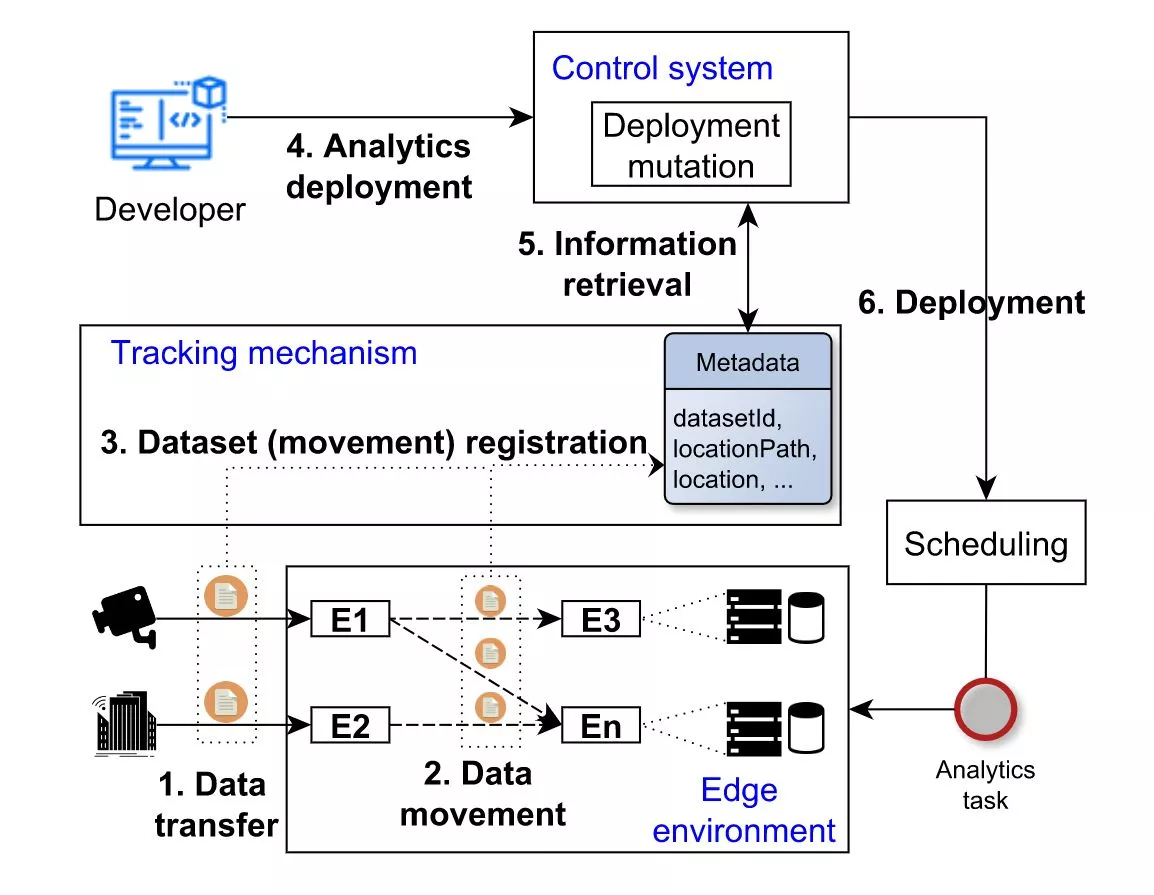
In Figure 1, we envision the scenario of self-adaptive analytics task deployment considering the data locality issue. A high-level overview of SAPLaw architecture illustrates three main entities (Edge environment, Tracking mechanism, and Control system) and six steps, namely:
- Data transfer. Here, data generated from different sensors are transferred to edge nodes, where they can be processed or stored for later analysis.
- Data movement. In this step, data can be moved, migrated or replicated to other nodes due to many reasons such as limited storage capacities and edge node failure probabilities.
- Dataset (movement) registration. Any dataset generation, as well as its replication or movement, are registered and updated within the tracking mechanism. Dataset metadata represents a collection of current location information for each dataset. This information can include storage location, dataset ID, location path, etc.
- Analytics deployment. The developer submits the analytics task to the control mechanism that takes care of the deployment object adaptation.
- Information retrieval. The control mechanism (i) reads a dataset ID, (ii) consults with the metadata server, (iii) retrieves dataset location and needed information, and (iv) updates the deployment object file.
- Deployment. Finally, the deployment object is sent to a scheduler that automatically retrieves the node candidates (in this case a specific node, based on location information) and places the analytics task to a node storing needed dataset.
Considering the deployment and management of containerized applications, many researchers and enterprises are revealing nowadays the rapid adoption of Kubernetes platform. Here, in order to deploy an application instance in Kubernetes, a docker image has to be included in the applications’ manifest file known as a deployment file. Further, Kubernetes uses a "pod" as a unit, referring to a group of application-specific containers. So, the analytics task (e.g., object detection or inference) in Figure 1 is represented as a pod that will be deployed to one of the edge nodes (workers).
Moreover, to realize the proposed approach of placing pods across available nodes, we need to understand two Kubernetes concepts, namely:
- Persistent Volume (PV) represents a piece of storage resource, usually provisioned by the administrator.
- Persistent Volume Claim (PVC) represents a declaration of the need for storage, and once it is bound to a PV it refers to a volume on the specific node. Specifying the PVC claim name within the deployment file, during a pod creation, the Kubernetes scheduler will automatically place a pod in the targeted node.
With this background and proposed system design, we aim to explore new possibilities of the automatic and self-adaptive placements of analytics tasks to distributed edge environments. Still, some steps (e.g., 4 and 5) need to be improved in the implementation. We expect that the experimental evaluation will show a promising solution and benefits for distributed cluster environments such as the hybrid cloud.






